ℹ️ Skipped - page is already crawled
| Filter | Status | Condition | Details |
|---|---|---|---|
| HTTP status | PASS | download_http_code = 200 | HTTP 200 |
| Age cutoff | PASS | download_stamp > now() - 6 MONTH | 0 months ago |
| History drop | PASS | isNull(history_drop_reason) | No drop reason |
| Spam/ban | PASS | fh_dont_index != 1 AND ml_spam_score = 0 | ml_spam_score=0 |
| Canonical | PASS | meta_canonical IS NULL OR = '' OR = src_unparsed | Not set |
| Property | Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| URL | https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/ | |||||||||
| Last Crawled | 2026-04-27 08:13:30 (1 day ago) | |||||||||
| First Indexed | 2024-08-13 01:53:35 (1 year ago) | |||||||||
| HTTP Status Code | 200 | |||||||||
| Content | ||||||||||
| Meta Title | Not Quite the James-Stein Estimator – econometrics.blog | |||||||||
| Meta Description | null | |||||||||
| Meta Canonical | null | |||||||||
| Boilerpipe Text | If you study enough econometrics or statistics, you’ll eventually hear someone mention “Stein’s Paradox” or the
“James-Stein Estimator”
. You’ve probably learned in your introductory econometrics course that ordinary least squares (OLS) is the
best linear unbiased estimator
(BLUE) in a linear regression model under the Gauss-Markov assumptions. The stipulations “linear” and “unbiased” are crucial here. If we remove them, it’s possible to do better–maybe even
much better
–than OLS.
1
Stein’s paradox is a famous example of this phenomenon, one that created much consternation among statisticians and fellow-travelers when it was first pointed out by
Charles Stein
in the mid-1950s. The example is interesting in its own right, but also has deep connections to ideas in Bayesian inference and machine learning making it much more than a mere curiosity.
The supposed
paradox
is most simply stated by considering a special case of linear regression–that of estimating multiple unknown means.
Efron & Morris (1977)
introduce the basic idea as follows:
A baseball player who gets seven hits in 20 official times at bat is said to have a batting average of .350. In computing this statistic we are forming an estimate of the player’s true batting ability in terms of his observed average rate of success. Asked how well the player will do in his next 100 times at bat, we would probably predict 35 more hits. In traditional statistical theory it can be proved that no other estimation rule is uniformly better than the observed average. The paradoxical element in Stein’s result is that it sometimes contradicts this elementary law of statistical theory. If we have three or more baseball players, and if we are interested in predicting future batting averages for each of them, then there is a procedure that is better than simply extrapolating from the three separate averages. Here “better” has a strong meaning. The statistician who employs Stein’s method can expect to predict the future averages more accurately no matter what the true batting abilities of the players may be.
I first encountered Stein’s Paradox in an offhand remark by my PhD supervisor. I dutifully looked it up in an attempt to better understand the point he had been making, but lacked sufficient understanding of decision theory at the time to see what the fuss was all about. The second time I encountered it, after I knew a bit more, it seemed astounding: almost like magic. I decided to include the topic in my
Econ 722
course at Penn, but struggled to make it accessible to my students. A big problem, in my view, is that the proof–see
lecture 1
or
section 7.3
–is ultimately a bit of a let-down: algebra, followed by repeated integration by parts, and then a fact about the existence of moments for an
inverse-chi-squared random variable
. It seems like a sterile technical exercise when in fact that result itself is deep, surprising, and important. As if a benign deity were keen on making my point for me, the wikipedia article on the
James-Stein Estimator
is flagged as “may be too technical for readers to understand” at the time of this writing!
After six months of pondering, this post is my attempt to explain the James-Stein Estimator in a way that is accessible to a broad audience. The assumed background is minimal: just an introductory course in probability and statistics. I’ll show how we can arrive at something that is
very nearly
the James-Stein estimator by following some very simple and natural intuition. After you understand my “not quite James-Stein” estimator, it’s a short step to the real thing. So the “let-down” proof I mentioned before becomes merely a technical justification for a slight modification of a formula that is already intuitively compelling. As far as possible, I’ve tried to keep this post self-contained by introducing, or at least reviewing, key background material as we go along. The cost of this approach, unfortunately, is that the post is pretty long! I hope you’ll soldier on to the end and that you’ll find the payoff worth your time and effort.
As far as I know, the precise way that I motivate the James-Stein estimator in this post is new, but there are many other papers that aim to make sense of the supposed paradox in an intuitive way. In keeping with my injunction that you should always consider
reading something else instead
, here are a few references that you may find helpful.
Efron & Morris (1977)
is a classic article aimed at the general reader without a background in statistics.
Stigler (1988)
is a more technical but still accessible discussion of the topic while
Casella (1985)
is a very readable paper that discusses the James-Stein estimator in the context of empirical Bayes. A less well-known paper that I found helpful is
Ijiri & Leitch (1980)
, who consider the James-Stein estimator in a real-world setting, namely “Audit Sampling” in accounting. They discuss several interesting practical and philosophical issues including the distinction between “composite” and “individual” risk that I’ll pick up on below.
Warm-up Exercise
This section provides some important background that we’ll need to understand Stein’s Paradox later in the post reviewing the ideas of
bias
,
variance
and
mean-squared error
along with introducing a very simple
shrinkage estimator
. To make these ideas as transparent as possible we’ll start with a ridiculously simple problem. Suppose that you observe
X
∼
Normal
(
μ
,
1
)
, a single draw from a normal distribution with variance one and unknown mean
μ
. Your task is to estimate
μ
. This may strike you as a very silly problem: it only involves a single datapoint and we assume the variance of
X
is one! But in fact there’s nothing special about
n
=
1
and a variance of one: these merely make the notation simpler. If you prefer, you can think of
X
as the sample mean of
n
iid draws from a population with unknown mean
μ
where we’ve
rescaled
everything to have variance one. So how should we estimate
μ
? A natural and reasonable idea is to use the sample mean, in this case
X
itself. This is in fact the
maximum likelihood estimator
for
μ
, so I’ll define
μ
^
ML
=
X
. But is this estimator any good? And can we find something better?
Review of Bias, Variance and MSE
The concepts of
bias
and
variance
are key ideas that we typically reach for when considering the quality of an estimator. To refresh your memory,
bias
is the difference between an estimators expected value and the true value of the parameter being estimated while
variance
is the expected squared difference between an estimator and its expected value. So if
θ
^
is an estimator of some unknown parameter
θ
, then
Bias
(
θ
^
)
=
E
[
θ
^
]
−
θ
while
Var
(
θ
^
)
=
E
[
(
θ
^
−
E
[
θ
^
]
)
2
]
. A bias of zero means that an estimator is
correctly centered
: its expectation equals the truth. We say that such an estimator is
unbiased
.
2
A small variance means that an estimator is
precise
: it doesn’t “jump around” too much. Ideally we’d like an estimator that is correctly centered and precise. But it turns out that there is generally a
trade-off
between bias and variance: if you want to reduce one of them, you have to accept an increase in the other.
A common way of trading off bias and variance relies on a concept called
mean-squared error
(MSE) defined as the
sum
of the squared bias and the variance.
3
In particular:
MSE
(
θ
^
)
=
Var
(
θ
^
)
+
Bias
(
θ
^
)
2
. Equivalently, we can write
MSE
(
θ
^
)
=
E
[
(
θ
^
−
θ
)
2
]
.
4
To borrow some terminology from introductory microeconomics, you can think of MSE as the
negative
of a utility function over bias and variance. Both bias and variance are “bads” in that we’d rather have less rather than more of each. This formula expresses our
preferences
in terms of how much of one we’d be willing to accept in exchange for less of the other. Slightly foreshadowing something that will come later in this post, we can think of MSE as the square of the average distance that an archer’s arrows land from the bulls-eye. Smaller values of MSE are better: variance measures how closely the arrows cluster together while bias measures how far the center of the cluster is from the bulls-eye, as in the following diagram:
A Shrinkage Estimator
Returning to our maximum likelihood estimator: it’s unbiased,
Bias
(
μ
^
ML
)
=
0
, so
MSE
(
μ
^
ML
)
=
Var
(
μ
^
ML
)
=
1
. Suppose that low MSE is what we’re after. Is there any way to improve on the ML estimator? In other words, can we achieve an MSE that’s lower than one? The answer turns out to be
yes
. Here’s the idea. Suppose we had some reason to believe that the true mean
μ
isn’t very large. Then perhaps we could try to adjust our maximum likelihood estimate by
shrinking
slightly towards zero. One way to do this would be by taking a weighted average of the ML estimator and zero:
μ
^
(
λ
)
=
(
1
−
λ
)
×
μ
^
ML
+
λ
×
0
=
(
1
−
λ
)
X
for
0
≤
λ
≤
1
. The constant
(
1
−
λ
)
is called the “shrinkage factor” and controls how the ML estimator gets pulled towards zero.
5
We get a different estimator for every value of
λ
. If
λ
=
0
then we get the ML estimator back. If
λ
=
1
then we get a very silly estimator that ignores the data and simply reports zero no matter what! So let’s see how the MSE depends on our choice of
λ
. Substituting the definition of
μ
^
(
λ
)
into the formulas for bias and variance gives:
Bias
[
μ
^
(
λ
)
]
=
E
[
(
1
−
λ
)
μ
^
ML
]
−
μ
=
(
1
−
λ
)
E
[
μ
^
ML
]
−
μ
=
(
1
−
λ
)
μ
−
μ
=
−
λ
μ
Var
[
μ
^
(
λ
)
]
=
Var
[
(
1
−
λ
)
μ
^
ML
]
=
(
1
−
λ
)
2
Var
[
μ
^
ML
]
=
(
1
−
λ
)
2
MSE
[
μ
^
(
λ
)
]
=
Var
[
μ
^
(
λ
)
]
+
Bias
[
μ
^
(
λ
)
]
2
=
(
1
−
λ
)
2
+
λ
2
μ
2
Unless
λ
=
0
, the shrinkage estimator is
biased
. And while the MSE of the ML estimator is always one, regardless of the true value of
μ
, the MSE of the shrinkage estimator
depends on the unknown parameter
μ
.
So why should we use a biased estimator? The answer is that by tolerating a small amount of bias we may be able to achieve a
larger
reduction in variance, resulting in a lower MSE compared to the higher variance but unbiased ML estimator. A quick plot shows us that the shrinkage estimator
can indeed
have a lower MSE than the ML estimator depending on the value of
λ
and the true value of
μ
:
# Range of values for the unknown parameter mu
mu
<-
seq
(
-
4
,
4
,
length =
100
)
# Try three different values of lambda
lambda1
<-
0.1
lambda2
<-
0.2
lambda3
<-
0.3
# Plot the MSE of the shrinkage estimator as a function of mu for all
# three values of lambda at once
matplot
(mu,
cbind
((
1
-
lambda1)
^
2
+
lambda1
^
2
*
mu
^
2
,
(
1
-
lambda2)
^
2
+
lambda2
^
2
*
mu
^
2
,
(
1
-
lambda3)
^
2
+
lambda3
^
2
*
mu
^
2
),
type =
'l'
,
lty =
1
,
lwd =
2
,
col =
c
(
'red'
,
'blue'
,
'green'
),
xlab =
expression
(mu),
ylab =
'MSE'
,
main =
'MSE of Shrinkage Estimator'
)
# Add legend
legend
(
'topright'
,
legend =
c
(
expression
(lambda
==
0.1
),
expression
(lambda
==
0.2
),
expression
(lambda
==
0.3
)),
col =
c
(
'red'
,
'blue'
,
'green'
),
lty =
1
,
lwd =
2
)
# Add dashed line for MSE of ML estimator
abline
(
h =
1
,
lty =
2
,
lwd =
2
)
Some Algebra
It’s time for some algebra. If you’re tempted to skip this
please don’t
: this section is a warm-up for our main event. If you thoroughly understand the mechanics of shrinkage in this simple example, everything that follows below will seem much more natural.
As seen from the plot above, the MSE of our shrinkage estimator (the solid lines) is lower than that of the ML estimator (the dashed line) provided that our chosen value of
λ
isn’t too large relative to the true value of
μ
. With a bit of algebra, we can work out
precisely
how large
λ
can be to make shrinkage worthwhile. Since
MSE
[
μ
^
ML
]
=
1
, by expanding and simplifying the expression for
MSE
[
μ
^
(
λ
)
]
we see that
MSE
[
μ
^
(
λ
)
]
<
MSE
[
μ
^
ML
]
if and only if
(
1
−
λ
)
2
+
λ
2
μ
2
<
1
1
−
2
λ
+
λ
2
+
λ
2
μ
2
<
1
λ
2
(
1
+
μ
2
)
−
2
λ
<
0
λ
[
λ
(
1
+
μ
2
)
−
2
]
<
0.
Since
λ
≥
0
, the final inequality can only hold if the factor inside the square brackets is negative, i.e.
λ
(
1
+
μ
2
)
−
2
<
0
λ
<
2
1
+
μ
2
.
This shows that any choice of
λ
between
0
and
2
/
(
1
+
μ
2
)
will give us a shrinkage estimator with an MSE less than one. To check our algebra, we can change the inequality to an equality and solve for
μ
to obtain the boundary of the region where shrinkage is better than ML:
λ
(
1
+
μ
2
)
−
2
=
0
1
+
μ
2
=
2
/
λ
μ
=
±
2
/
λ
−
1
.
Adding these boundaries to a simplified version of our previous plot with only
λ
=
0.3
we see that everything works out correctly: the dashed red lines intersect the blue curve at the points where the MSE of the shrinkage estimator equals that of the ML estimator.
# Plot the MSE of the shrinkage estimator as a function of mu for lambda = 0.3
lambda
<-
0.3
plot
(mu, (
1
-
lambda)
^
2
+
lambda
^
2
*
mu
^
2
,
type =
'l'
,
lty =
1
,
lwd =
2
,
col =
'blue'
,
xlab =
expression
(mu),
ylab =
'MSE'
,
main =
'Boundary of Region Where Shrinkage is Better than ML'
)
# Add dashed line for MSE of ML estimator
abline
(
h =
1
,
lty =
2
,
lwd =
2
)
# Add boundaries of region where shrinkage is better than ML estimator
abline
(
v =
c
(
sqrt
(
2
/
lambda
-
1
),
-
sqrt
(
2
/
lambda
-
1
)),
lty =
3
,
lwd =
2
,
col =
'red'
)
But there’s still more to learn! Suppose we wanted to take things
one step further
and find the
optimal
value of
λ
for any given value of
μ
. In other words, suppose we wanted the value of
λ
that
minimizes
the MSE of our shrinkage estimator given a particular assumed value for
μ
. Since
MSE
[
μ
^
(
λ
)
]
is a quadratic function of
λ
, as shown above, this turns out to be a fairly straightforward calculation. Differentiating,
d
d
λ
MSE
[
μ
^
(
λ
)
]
=
d
d
λ
[
(
1
−
λ
)
2
+
λ
2
μ
2
]
=
−
2
(
1
−
λ
)
+
2
λ
μ
2
=
2
[
λ
(
1
+
μ
2
)
−
1
]
d
2
d
λ
2
MSE
[
μ
^
(
λ
)
]
=
2
(
1
+
μ
2
)
>
0
so there is a unique global minimum at
λ
∗
≡
1
/
(
1
+
μ
2
)
. This gives the
optimal
shrinkage factor in the sense that it minimizes the MSE of the shrinkage estimator. Substituting
λ
∗
into the expression for
MSE
[
μ
^
(
λ
)
]
gives:
MSE
[
μ
^
(
λ
∗
)
]
=
(
1
−
1
1
+
μ
2
)
2
+
(
1
1
+
μ
2
)
2
μ
2
=
(
μ
2
1
+
μ
2
)
2
+
(
1
1
+
μ
2
)
2
μ
2
=
(
1
1
+
μ
2
)
2
(
μ
4
+
μ
2
)
=
(
1
1
+
μ
2
)
2
μ
2
(
1
+
μ
2
)
=
μ
2
1
+
μ
2
<
1.
Stein’s Paradox
Recap
We’re moments away from having all the ingredients we need to introduce Stein’s Paradox! But first let’s review what we’ve uncovered thus far. We’ve seen that the shrinkage estimator can improve on the ML estimator in terms of MSE provided that
λ
is chosen judiciously: it needs to be between zero and
2
/
(
1
+
μ
2
)
. The optimal choice of
λ
, namely
λ
∗
=
1
/
(
1
+
μ
2
)
, gives an MSE of
μ
2
/
(
1
+
μ
2
)
. This is always lower than one, the MSE of the ML estimator.
There’s just one massive problem we’ve ignored this whole time:
we don’t know the value of
μ
! As seen from the figure plotted above, the MSE curves for different values of
λ
cross each other
: the best one to use depends on the true value of
μ
. This doesn’t mean that all is lost. Perhaps in practice we have some outside information about the likely value of
μ
that could help guide our choice of
λ
. What it does mean is that there’s no “one-size-fits-all” value.
Admissibility
It’s time to introduce a bit of technical vocabulary. We say that an estimator
θ
~
dominates
another estimator
θ
^
if
MSE
[
θ
~
]
≤
MSE
[
θ
^
]
for
all
possible values of the parameter
θ
being estimated and
MSE
[
θ
~
]
<
MSE
[
θ
^
]
for at least
one
possible value of
θ
.
6
In words, this means that it never makes sense to use
θ
^
in preference to
θ
~
. No matter what the true parameter value is, you can’t do worse with
θ
~
and you might do better. An estimator that is
not dominated
by any other estimator is called
admissible
; an estimator that
is dominated
by some other estimator is called
inadmissible
. The concept of
admissibility
in decision theory is a bit like the concept of
Pareto efficiency
in microeconomics. An admissible estimator is only “good” in the sense that it doesn’t leave any money on the table: there’s no way to do better for one parameter value without doing worse for another. In a similar way, a Pareto efficient allocation in economics is one in which no individual can be made better off without making another person worse off.
It’s quite challenging to prove, but in fact the ML estimator
θ
^
M
L
=
X
turns out to be admissible in our little example. So while we could potentially do better by using shrinkage, it’s not a slam-dunk case. If we really have no idea of how large
μ
is likely to be, the ML estimator is a reasonable choice. Because it’s admissible, at the very least we know that there’s no free lunch!
A More General Example
Now let’s make things a bit more interesting. For the rest of this post, suppose that we observe not a single draw
X
from a
Normal
(
μ
,
1
)
distribution but a
collection
of
p
independent draws from
p
different
normal distributions:
X
1
,
X
2
,
.
.
.
,
X
p
∼
independent Normal
(
μ
j
,
1
)
,
j
=
1
,
.
.
.
,
p
.
You can think of this as
p
copies of our original problem: we observe
X
j
∼
Normal
(
μ
j
,
1
)
and our task is to estimate
μ
j
. The observations are all independent, and each comes from a distribution with a potentially
different mean
. At first glance it seems like these
p
separate problems should have
absolutely nothing to do with each other
. And indeed the maximum likelihood estimator for the collection of
p
means is simply
μ
^
ML
(
j
)
=
X
j
. As above in our example with
p
=
1
, the question is: how good is the ML estimator, and can we do any better?
Composite MSE
But first things first: how can we evaluate the quality of
p
estimators for
p
different parameters
at the same time
? A common approach, and the one we will follow here, is to take the
sum
of the individual MSEs of each estimator, yielding a quantity called
composite MSE
. If
μ
^
1
,
μ
^
2
,
…
,
μ
^
p
is a collection of estimators for each of the individual unknown means, then the composite MSE is defined as
Composite MSE
≡
∑
j
=
1
p
MSE
(
μ
^
j
)
=
∑
j
=
1
p
[
Bias
(
μ
^
j
)
2
+
Var
(
μ
^
j
)
]
=
∑
j
=
1
p
E
[
(
μ
^
j
−
μ
j
)
2
]
.
Adopting composite MSE as our measure of
good
performance means that we view each of the
p
estimation problems as in some way “interchangeable”–we’re happy to accept a trade in which we do a slightly worse job estimating
μ
j
in exchange for doing a much better job estimating
μ
k
. At the end of the post I’ll say a few more words about this idea and when it may or may not be reasonable. But for the rest of the post, we will assume that our goal is to
minimize the composite MSE
. The concept of composite MSE will be crucial in understanding why the James-Stein estimator works the way it does.
Stein’s Paradox
Putting our new idea into practice, we see that the composite MSE of the ML estimator is
p
regardless of the true values of the individual means
μ
1
,
…
,
μ
p
since
∑
j
=
1
p
MSE
[
μ
^
ML
(
j
)
]
=
∑
j
=
1
p
MSE
(
X
j
)
=
∑
j
=
1
p
Var
(
X
j
)
=
p
.
If the ML estimator is admissible, then there should be no other estimator that always has an MSE less than or equal to
p
and sometimes has an MSE strictly less than
p
. I’ve already told you that this is true when
p
=
1
. When
p
=
2
it’s still true: the ML estimator remains admissible. But when
p
≥
3
something very unexpected happens: it becomes possible to construct an estimator that
dominates
the ML estimator by using information from
all
of the
(
X
1
,
.
.
.
,
X
p
)
observations to estimate
μ
j
. This is spite of the fact that there is
no obvious connection
between the observations. Again: they are all independent and come from distributions with different means!
The estimator that does the trick is the so-called “James-Stein Estimator” (JS), defined according to
μ
^
JS
(
j
)
=
(
1
−
p
−
2
∑
k
=
1
p
X
k
2
)
X
j
.
This estimator dominates the ML estimator when
p
≥
3
in that
∑
j
=
1
p
MSE
[
μ
^
JS
(
j
)
]
≤
∑
j
=
1
p
MSE
[
μ
^
ML
(
j
)
]
=
p
for
all
possible values of the
p
unknown means
μ
j
with strict inequality for at least
some
values. Taking a closer look at the formula, we see that the James-Stein estimator is just a
shrinkage
estimator applied to each of the
p
means, namely
μ
^
JS
(
j
)
=
(
1
−
λ
^
JS
)
X
j
,
λ
^
JS
≡
p
−
2
∑
k
=
1
p
X
k
2
.
The shrinkage factor in the James-Stein estimator depends on the number of means we’re estimating,
p
, along with the
overall
sum of the squared observations. All else equal, the more parameters we need to estimate, the more we shrink each of them towards zero. And the farther the observations are from zero
overall
, the less we shrink
each of them
towards zero.
Just like our simple shrinkage estimator from above, the James-Stein estimator achieves a lower MSE by tolerating a small bias in exchange for a larger reduction in variance, compared to the higher-variance but unbiased ML estimator. Unlike our simple shrinkage estimator, the James-Stein estimator uses the
data
to determine the shrinkage factor. And as long as
p
≥
3
it is always
at least as good
as the ML estimator and sometimes
much better
. The
paradox
is that this seems impossible: how can information from
all
of the observations be useful when they come from
different
distributions with no obvious connection?
The rest of this post will
not
prove that the James-Stein estimator dominates the ML estimator. Instead it will try to convince you that there is some
very good intuition
for why the formula for the James-Stein estimator takes the form it does. By the end, I hope you’ll feel that, far from seeming paradoxical, using
all
of the observations to determine the shrinkage factor for one particular
μ
j
makes perfect sense.
Where does the James-Stein Estimator Come From?
An Infeasible Estimator When
p
=
2
To start the ball rolling, let’s
assume a can-opener
: suppose that we don’t know any of the
individual
means
μ
j
but for some strange reason a benevolent deity has told us the value of their sum of squares:
c
2
≡
∑
j
=
1
p
μ
j
2
.
It turns out that this is enough information to construct a shrinkage estimator that
always
has a lower composite MSE than the ML estimator. Let’s see why this is the case. If
p
=
1
, then telling you
c
2
is the same as telling you
μ
2
. Granted, knowledge of
μ
2
isn’t as informative as knowledge of
μ
. For example, if I told you that
μ
2
=
9
you couldn’t tell whether
μ
=
3
or
μ
=
−
3
. But, as we showed above, the optimal shrinkage estimator when
p
=
1
sets
λ
∗
=
1
/
(
1
+
μ
2
)
and yields an MSE of
μ
2
/
(
1
+
μ
2
)
<
1
. Since
λ
∗
only depends on
μ
through
μ
2
, we’ve
already shown
that knowledge of
c
2
allows us to construct a shrinkage estimator that dominates the ML estimator when
p
=
1
.
So what if
p
equals 2? In this case, knowledge of
c
2
=
μ
1
2
+
μ
2
2
is equivalent to knowing the
radius
of a circle centered at the origin in the
(
μ
1
,
μ
2
)
plane where the two unknown means must lie. For example, if I told you that
c
2
=
1
you would know that
(
μ
1
,
μ
2
)
lies somewhere on a circle of radius one centered at the origin. As illustrated in the following plot, the points
(
x
1
,
x
2
)
and
(
y
1
,
y
2
)
would then be potential values of
(
μ
1
,
μ
2
)
as would all other points on the blue circle.
So how can we construct a shrinkage estimator of
(
μ
1
,
μ
2
)
with lower composite MSE than the ML estimator if
c
2
is known? While there are other possibilities, the simplest would be to use the
same
shrinkage factor for each of the two coordinates. In other words, our estimator would be
μ
^
1
(
λ
)
=
(
1
−
λ
)
X
1
,
μ
^
2
(
λ
)
=
(
1
−
λ
)
X
2
for some
λ
between zero and one. The composite MSE of this estimator is just the sum of the MSE of each
individual
component, so we can re-use our algebra from above to obtain
MSE
[
μ
^
1
(
λ
)
]
+
MSE
[
μ
^
2
(
λ
)
]
=
[
(
1
−
λ
)
2
+
λ
2
μ
1
2
]
+
[
(
1
−
λ
)
2
+
λ
2
μ
2
2
]
=
2
(
1
−
λ
)
2
+
λ
2
(
μ
1
2
+
μ
2
2
)
=
2
(
1
−
λ
)
2
+
λ
2
c
2
.
Notice that the composite MSE only depends on
(
μ
1
,
μ
2
)
through their sum of squares,
c
2
. Differentiating with respect to
λ
, just as we did above in the
p
=
1
case,
d
d
λ
[
2
(
1
−
λ
)
2
+
λ
2
c
2
]
=
−
4
(
1
−
λ
)
+
2
λ
c
2
=
2
[
λ
(
2
+
c
2
)
−
2
]
d
2
d
λ
2
[
2
(
1
−
λ
)
2
+
λ
2
c
2
]
=
2
(
2
+
c
2
)
>
0
so there is a unique global minimum at
λ
∗
=
2
/
(
2
+
c
2
)
. Substituting this value of
λ
into the expression for the composite MSE, a few lines of algebra give
MSE
[
μ
^
1
(
λ
∗
)
]
+
MSE
[
μ
^
2
(
λ
∗
)
]
=
2
(
1
−
2
2
+
c
2
)
2
+
(
2
2
+
c
2
)
2
c
2
=
2
(
c
2
2
+
c
2
)
.
Since
c
2
/
(
2
+
c
2
)
<
1
for all
c
2
>
0
, the optimal shrinkage estimator
always
has a composite MSE less than
2
, the composite MSE of the ML estimator. Strictly speaking this estimator is
infeasible
since we don’t know
c
2
. But it’s a crucial step on our journey to make the leap from applying shrinkage to an estimator for a
single
unknown mean, to using the same idea for
more than one
unknown mean.
A Simulation Experiment for
p
=
2
You may have already noticed that it’s easy to generalize this argument to
p
>
2
. But before we consider the general case, let’s take a moment to understand the geometry of shrinkage estimation for
p
=
2
a bit more deeply. The nice thing about two-dimensional problems is that they’re easy to plot. So here’s a graphical representation of both the ML estimator and our infeasible optimum shrinkage estimator when
p
=
2
. I’ve set the true, unknown, values of
μ
1
and
μ
2
to one so the true value of
c
2
is
2
and the optimal choice of
λ
is
λ
∗
=
2
/
(
2
+
c
2
)
=
2
/
4
=
0.5
. The following R code simulates our estimators and visualizes their performance, helping us see the shrinkage effect in action.
set.seed
(
1983
)
nreps
<-
50
mu1
<-
mu2
<-
1
x1
<-
mu1
+
rnorm
(nreps)
x2
<-
mu2
+
rnorm
(nreps)
csq
<-
mu1
^
2
+
mu2
^
2
lambda
<-
csq
/
(
2
+
csq)
par
(
mfrow =
c
(
1
,
2
))
# Left panel: ML Estimator
plot
(x1, x2,
main =
'MLE'
,
pch =
20
,
col =
'black'
,
cex =
2
,
xlab =
expression
(mu[
1
]),
ylab =
expression
(mu[
2
]))
abline
(
v =
mu1,
lty =
1
,
col =
'red'
,
lwd =
2
)
abline
(
h =
mu2,
lty =
1
,
col =
'red'
,
lwd =
2
)
# Add MSE to the plot
text
(
x =
2
,
y =
3
,
labels =
paste
(
"MSE ="
,
round
(
mean
((x1
-
mu1)
^
2
+
(x2
-
mu2)
^
2
),
2
)))
# Right panel: Shrinkage Estimator
plot
(x1, x2,
main =
'Shrinkage'
,
xlab =
expression
(mu[
1
]),
ylab =
expression
(mu[
2
]))
points
(lambda
*
x1, lambda
*
x2,
pch =
20
,
col =
'blue'
,
cex =
2
)
segments
(
x0 =
x1,
y0 =
x2,
x1 =
lambda
*
x1,
y1 =
lambda
*
x2,
lty =
2
)
abline
(
v =
mu1,
lty =
1
,
col =
'red'
,
lwd =
2
)
abline
(
h =
mu2,
lty =
1
,
col =
'red'
,
lwd =
2
)
abline
(
v =
0
,
lty =
1
,
lwd =
2
)
abline
(
h =
0
,
lty =
1
,
lwd =
2
)
# Add MSE to the plot
text
(
x =
2
,
y =
3
,
labels =
paste
(
"MSE ="
,
round
(
mean
((lambda
*
x1
-
mu1)
^
2
+
(lambda
*
x2
-
mu2)
^
2
),
2
)))
My plot has two panels. The left panel shows the raw data. Each black point is a pair
(
X
1
,
X
2
)
of independent normal draws with means
(
μ
1
=
1
,
μ
2
=
1
)
and variances
(
1
,
1
)
. As such, each point is also the
ML estimate
(MLE) of
(
μ
1
,
μ
2
)
based on
(
X
1
,
X
2
)
. The red cross shows the location of the true values of
(
μ
1
,
μ
2
)
, namely
(
1
,
1
)
. There are 50 points in the plot, representing 50 replications of the simulation, each independent of the rest and with the same parameter values. This allows us to measure how close the ML estimator is to the true value of
(
μ
1
,
μ
2
)
in repeated sampling, approximating the composite MSE.
The right panel is more complicated. This shows
both
the ML estimates (unfilled black circles)
and
the corresponding shrinkage estimates (filled blue circles) along with dashed lines connecting them. Each shrinkage estimate is constructed by “pulling” the corresponding MLE towards the origin by a factor of
λ
=
0.5
. Thus, if a given unfilled black circle is located at
(
X
1
,
X
2
)
, the corresponding filled blue circle is located at
(
0.5
X
1
,
0.5
X
2
)
. As in the left panel, the red cross in the right panel shows the true values of
(
μ
1
,
μ
2
)
, namely
(
1
,
1
)
. The black cross, on the other hand, shows the point towards which the shrinkage estimator pulls the ML estimator, namely
(
0
,
0
)
.
We see immediately that the ML estimator is
unbiased
: the black filled dots in the left panel (along with the unfilled ones in the right) are centered at
(
1
,
1
)
. But the ML estimator is also
high-variance
: the black dots are quite spread out around
(
1
,
1
)
. We can approximate the composite MSE of the ML estimator by computing the average squared Euclidean distance between the black points and the red cross.
7
And in keeping with our theoretical calculations, the simulation gives a composite MSE of almost exactly 2 for the ML estimator.
In contrast, the optimal shrinkage estimator is
biased
: the filled blue dots in the right panel centered somewhere between the red cross (the true means) and the origin. But the shrinkage estimator also has a lower variance: the filled blue dots are much closer together than the black ones. Even more importantly
they are on average closer to
(
μ
1
,
μ
2
)
, as indicated by the red cross and as measured by composite MSE. Our theoretical calculations showed that the composite MSE of the optimal shrinkage estimator equals
2
c
2
/
(
2
+
c
2
)
. When
c
2
=
2
, as in this case, we obtain
2
×
2
/
(
2
+
2
)
=
1
. Again, this is almost exactly what we see in the simulation.
If we had used more than 50 simulation replications, the composite MSE values would have been even closer to our theoretical predictions, at the cost of making the plot much harder to read! But I hope the key point is still clear: shrinkage
pulls
the MLE towards the origin, and can give a
much
lower composite MSE.
An Infeasible Estimator: The General Case
Now that we understand the case of
p
=
2
, the general case is a snap. Our shrinkage estimator of each
μ
j
will take the form
μ
^
j
(
λ
)
=
(
1
−
λ
)
X
j
,
j
=
1
,
…
,
p
for some
λ
between zero and one. To find the optimal choice of
λ
, we minimize
∑
j
=
1
p
MSE
[
μ
^
j
(
λ
)
]
=
∑
j
=
1
p
[
(
1
−
λ
)
2
+
λ
2
μ
j
2
]
=
p
(
1
−
λ
)
2
+
λ
2
c
2
with respect to
λ
. Again, the key is that the composite MSE only depends on the unknown means through
c
2
. Using almost exactly the same calculations as above for the case of
p
=
2
, we find that
λ
∗
=
p
p
+
c
2
,
∑
j
=
1
p
MSE
[
μ
^
j
(
λ
∗
)
]
=
p
(
c
2
p
+
c
2
)
.
since
c
2
/
(
p
+
c
2
)
<
1
for all
c
2
>
0
, the optimal shrinkage estimator
always
has a composite MSE less than
p
, the composite MSE of the ML estimator.
Not Quite the James-Stein Estimator
The end is in sight! We’ve shown that if we knew the sum of squares of the unknown means,
c
2
, we could construct a shrinkage estimator that always has a lower composite MSE than the ML estimator. But we don’t know
c
2
. So what can we do? To start off, re-write
λ
∗
as follows
λ
∗
=
p
p
+
c
2
=
1
1
+
c
2
/
p
.
This way of writing things makes it clear that it’s not
c
2
per se
that matters but rather
c
2
/
p
. And this quantity is simply is the
average
of the unknown squared means:
c
2
p
=
1
p
∑
j
=
1
p
μ
j
2
.
So how could we learn
c
2
/
p
? An idea that immediately suggests itself is to estimate this quantity by replacing each unobserved
μ
j
with the corresponding observation
X
j
, in other words
1
p
∑
j
=
1
p
X
j
2
.
This is a good starting point, but we can do better. Since
X
j
∼
Normal
(
μ
j
,
1
)
, we see that
E
[
1
p
∑
j
=
1
p
X
j
2
]
=
1
p
∑
j
=
1
p
E
[
X
j
2
]
=
1
p
∑
j
=
1
p
[
Var
(
X
j
)
+
E
(
X
j
)
2
]
=
1
p
∑
j
=
1
p
(
1
+
μ
j
2
)
=
1
+
c
2
p
.
This means that
(
∑
j
=
1
p
X
j
2
)
/
p
will on average
overestimate
c
2
/
p
by one. But that’s a problem that’s easy to fix: simply subtract one! This is a rare situation in which there is
no bias-variance tradeoff
. Subtracting a constant, in this case one, doesn’t contribute any additional variation while completely removing the bias. Plugging into our formula for
λ
∗
, this suggests using the estimator
λ
^
≡
1
1
+
[
(
1
p
∑
j
=
1
p
X
j
2
)
−
1
]
=
1
1
p
∑
j
=
1
p
X
j
2
=
p
∑
j
=
1
p
X
j
2
as our stand-in for the unknown
λ
∗
, yielding a shrinkage estimator that I’ll call “NQ” for “not quite” for reasons that will become apparent in a moment:
μ
^
NQ
(
j
)
=
(
1
−
p
∑
k
=
1
p
X
k
2
)
X
j
.
Notice what’s happening here: our optimal shrinkage estimator depends on
c
2
/
p
, something we can’t observe. But we’ve constructed an
unbiased estimator
of this quantity by using
all of the observations
X
j
. This is the resolution of the paradox discussed above: all of the observations contain information about
c
2
since this is simply the sum of the squared means. And because we’ve chosen to minimize composite MSE, the optimal shrinkage factor only depends on the individual
μ
j
parameters through
c
2
! This is the sense in which it’s possible to learn something useful about, say,
μ
1
from
X
2
in spite of the fact that
E
[
X
2
]
=
μ
2
may bear no relationship to
μ
1
.
But wait a minute! This looks
suspiciously familiar
. Recall that the James-Stein estimator is given by
μ
^
JS
(
j
)
=
(
1
−
p
−
2
∑
k
=
1
p
X
k
2
)
X
j
.
Just like the JS estimator, my NQ estimator shrinks each of the
p
means towards zero by a factor that depends on the number of means we’re estimating,
p
, and the overall sum of the squared observations. The key difference between JS and NQ is that JS uses
p
−
2
in the numerator instead of
p
. This means that NQ is a more “aggressive” shrinkage estimator than JS: it pulls the means towards zero by a larger amount than JS. This difference turns out to be crucial for proving that the JS estimator dominates the ML estimator. But when it comes to understanding why the JS estimator has the
form
that it does, I would argue that the difference is minor. If you want all the gory details of where that extra
−
2
comes from, along with the closely related issue of why
p
≥
3
is crucial for JS to dominate the ML estimator, see
lecture 1
or
section 7.3
from my Econ 722 teaching materials.
Conclusion
Before we conclude, there’s one important caveat to bear in mind. In addition to the qualifications that NQ isn’t
quite
JS, and that JS only dominates the MLE when
p
≥
3
, there’s one more fundamental issue that could be easily missed. Our decision to minimize
composite
MSE is
absolutely crucial
to the reasoning given above. The magic of shrinkage depends on our willingness to accept a trade-off in which we do a worse job estimating one mean in exchange for doing a better job estimating another, as composite MSE imposes. Whether this makes sense in practice depends on the context.
If we’re searching for a lost submarine in the ocean (a 3-dimensional problem), it makes perfect sense to be willing to be farther from the submarine in one dimension in exchange for being closer in another. That’s because
Euclidean distance
is obviously what we’re after here. But if instead we’re estimating
teacher value-added
and the results of our estimation exercise will be used to determine which teachers lose their jobs, it’s less clear that we should be willing to be farther from one teacher in exchange for being closer to another. Certainly that would be no consolation to someone who had been wrongly dismissed! If we were merely using this information to identify teachers who might need extra help, it’s another story. But the point I’m trying to make here is that our choice of which criterion to minimize necessarily encodes our
values
in a particular problem.
But with that said, I hope you’re satisfied that this extremely long post was worth the effort. Without using any fancy mathematics or statistical theory, we’ve managed to invent something that is
nearly identical
to the James-Stein estimator and thus to resolve Stein’s paradox. We started by pretending what we knew
c
2
and showed that this would allow us to derive a shrinkage estimator with a lower composite MSE than the ML estimator. Then we simply plugged in an unbiased estimator of the key unknown quantity:
c
2
/
p
. Because all the observations contain information about
c
2
, it makes sense that we should decide how much to shrink one component
X
j
by using all of the others. At this point, I hope that the James-Stein estimator seems not only plausible but practically
obvious
, excepting of course that pesky
−
2
in the numerator.
Footnotes
If I ruled the universe, the Gauss-Markov Theorem would be demoted to much less exalted status in econometrics teaching!
↩︎
Don’t let words do your thinking for you: “bias” sounds like a very bad thing, like kicking puppies. But that’s because the word “bias” has a negative connotation in English. In statistics, it’s just a technical term for “not centered”. An estimator can be biased and still be very good. Indeed the punchline of this post is that the James-Stein estimator is biased but can be much better than the obvious alternative!
↩︎
Why squared bias and not simply bias itself? The answer is units: bias is measured in the same units as the parameter being estimated while the variance is in squared units. It doesn’t make sense to add things with different units, so we either have to square the bias or take the square root of the variance, i.e. replace it with the standard deviation. But bias can be negative, and we wouldn’t want a large negative bias to cancel out a large standard deviation so MSE squares the bias instead.
↩︎
See if you can prove this as a homework exercise!
↩︎
In Bayesian terms, we could view this “shrinkage” idea as calculating the posterior mean of
μ
conditional on our data
X
under a normal prior. In this case
λ
would equal
τ
/
(
1
+
τ
)
where
τ
is the
prior precision
, i.e. the reciprocal of the prior variance. But for this post we’ll mainly stick to the Frequentist perspective.
↩︎
Strictly speaking all of this pre-supposes that we’re working with squared-error loss so that MSE is the right thing to minimize. There are other loss functions we could have used instead and these would lead to different risk functions. But for the purposes of this post, I prefer to keep things simple. See
lecture 1
of my Econ 722 slides for more detail.
↩︎
Remember that there are two equivalent definitions of MSE: bias squared plus variance on the one hand and expected squared distance from the truth on the other hand.
↩︎ | |||||||||
| Markdown | [econometrics.blog](https://www.econometrics.blog/)
- [Home](https://www.econometrics.blog/)
- [About](https://www.econometrics.blog/about/)
## On this page
- [Warm-up Exercise](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#warm-up-exercise)
- [Review of Bias, Variance and MSE](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#review-of-bias-variance-and-mse)
- [A Shrinkage Estimator](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#a-shrinkage-estimator)
- [Some Algebra](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#some-algebra)
- [Stein’s Paradox](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#steins-paradox)
- [Recap](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#recap)
- [Admissibility](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#admissibility)
- [A More General Example](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#a-more-general-example)
- [Composite MSE](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#composite-mse)
- [Stein’s Paradox](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#steins-paradox-1)
- [Where does the James-Stein Estimator Come From?](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#where-does-the-james-stein-estimator-come-from)
- [An Infeasible Estimator When p = 2](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#an-infeasible-estimator-when-p-2)
- [A Simulation Experiment for p = 2](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#a-simulation-experiment-for-p-2)
- [An Infeasible Estimator: The General Case](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#an-infeasible-estimator-the-general-case)
- [Not Quite the James-Stein Estimator](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#not-quite-the-james-stein-estimator)
- [Conclusion](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#conclusion)
# Not Quite the James-Stein Estimator
[statistics](https://www.econometrics.blog/index.html#category=statistics)
Author
Francis J. DiTraglia
Published
August 10, 2024
If you study enough econometrics or statistics, you’ll eventually hear someone mention “Stein’s Paradox” or the [“James-Stein Estimator”](https://en.wikipedia.org/wiki/James%E2%80%93Stein_estimator). You’ve probably learned in your introductory econometrics course that ordinary least squares (OLS) is the [best linear unbiased estimator](https://en.wikipedia.org/wiki/Gauss%E2%80%93Markov_theorem) (BLUE) in a linear regression model under the Gauss-Markov assumptions. The stipulations “linear” and “unbiased” are crucial here. If we remove them, it’s possible to do better–maybe even *much better*–than OLS.[1](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn1) Stein’s paradox is a famous example of this phenomenon, one that created much consternation among statisticians and fellow-travelers when it was first pointed out by [Charles Stein](https://en.wikipedia.org/wiki/Charles_M._Stein) in the mid-1950s. The example is interesting in its own right, but also has deep connections to ideas in Bayesian inference and machine learning making it much more than a mere curiosity.
The supposed [paradox](https://youtu.be/XXhJKzI1u48?si=cS--uLd09_JnAXdr) is most simply stated by considering a special case of linear regression–that of estimating multiple unknown means. [Efron & Morris (1977)](https://www.jstor.org/stable/24954030) introduce the basic idea as follows:
> A baseball player who gets seven hits in 20 official times at bat is said to have a batting average of .350. In computing this statistic we are forming an estimate of the player’s true batting ability in terms of his observed average rate of success. Asked how well the player will do in his next 100 times at bat, we would probably predict 35 more hits. In traditional statistical theory it can be proved that no other estimation rule is uniformly better than the observed average. The paradoxical element in Stein’s result is that it sometimes contradicts this elementary law of statistical theory. If we have three or more baseball players, and if we are interested in predicting future batting averages for each of them, then there is a procedure that is better than simply extrapolating from the three separate averages. Here “better” has a strong meaning. The statistician who employs Stein’s method can expect to predict the future averages more accurately no matter what the true batting abilities of the players may be.
I first encountered Stein’s Paradox in an offhand remark by my PhD supervisor. I dutifully looked it up in an attempt to better understand the point he had been making, but lacked sufficient understanding of decision theory at the time to see what the fuss was all about. The second time I encountered it, after I knew a bit more, it seemed astounding: almost like magic. I decided to include the topic in my [Econ 722](https://ditraglia.com/econ722) course at Penn, but struggled to make it accessible to my students. A big problem, in my view, is that the proof–see [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) or [section 7.3](https://ditraglia.com/econ722/main.pdf)–is ultimately a bit of a let-down: algebra, followed by repeated integration by parts, and then a fact about the existence of moments for an [inverse-chi-squared random variable](https://en.wikipedia.org/wiki/Inverse-chi-squared_distribution). It seems like a sterile technical exercise when in fact that result itself is deep, surprising, and important. As if a benign deity were keen on making my point for me, the wikipedia article on the [James-Stein Estimator](https://en.wikipedia.org/wiki/James%E2%80%93Stein_estimator) is flagged as “may be too technical for readers to understand” at the time of this writing\!
After six months of pondering, this post is my attempt to explain the James-Stein Estimator in a way that is accessible to a broad audience. The assumed background is minimal: just an introductory course in probability and statistics. I’ll show how we can arrive at something that is *very nearly* the James-Stein estimator by following some very simple and natural intuition. After you understand my “not quite James-Stein” estimator, it’s a short step to the real thing. So the “let-down” proof I mentioned before becomes merely a technical justification for a slight modification of a formula that is already intuitively compelling. As far as possible, I’ve tried to keep this post self-contained by introducing, or at least reviewing, key background material as we go along. The cost of this approach, unfortunately, is that the post is pretty long! I hope you’ll soldier on to the end and that you’ll find the payoff worth your time and effort.
As far as I know, the precise way that I motivate the James-Stein estimator in this post is new, but there are many other papers that aim to make sense of the supposed paradox in an intuitive way. In keeping with my injunction that you should always consider [reading something else instead](https://www.econometrics.blog/post/how-to-read-an-econometrics-paper/), here are a few references that you may find helpful. [Efron & Morris (1977)](https://www.jstor.org/stable/24954030) is a classic article aimed at the general reader without a background in statistics. [Stigler (1988)](https://projecteuclid.org/journals/statistical-science/volume-5/issue-1/The-1988-Neyman-Memorial-Lecture--A-Galtonian-Perspective-on/10.1214/ss/1177012274.full) is a more technical but still accessible discussion of the topic while [Casella (1985)](https://www.jstor.org/stable/2682801) is a very readable paper that discusses the James-Stein estimator in the context of empirical Bayes. A less well-known paper that I found helpful is [Ijiri & Leitch (1980)](https://www.jstor.org/stable/2490394), who consider the James-Stein estimator in a real-world setting, namely “Audit Sampling” in accounting. They discuss several interesting practical and philosophical issues including the distinction between “composite” and “individual” risk that I’ll pick up on below.
## Warm-up Exercise
This section provides some important background that we’ll need to understand Stein’s Paradox later in the post reviewing the ideas of **bias**, **variance** and **mean-squared error** along with introducing a very simple **shrinkage estimator**. To make these ideas as transparent as possible we’ll start with a ridiculously simple problem. Suppose that you observe X ∼ Normal ( μ , 1 ), a single draw from a normal distribution with variance one and unknown mean μ. Your task is to estimate μ. This may strike you as a very silly problem: it only involves a single datapoint and we assume the variance of X is one! But in fact there’s nothing special about n \= 1 and a variance of one: these merely make the notation simpler. If you prefer, you can think of X as the sample mean of n iid draws from a population with unknown mean μ where we’ve *rescaled* everything to have variance one. So how should we estimate μ? A natural and reasonable idea is to use the sample mean, in this case X itself. This is in fact the [maximum likelihood estimator](https://en.wikipedia.org/wiki/Maximum_likelihood_estimation) for μ, so I’ll define μ ^ ML \= X. But is this estimator any good? And can we find something better?
### Review of Bias, Variance and MSE
The concepts of *bias* and *variance* are key ideas that we typically reach for when considering the quality of an estimator. To refresh your memory, *bias* is the difference between an estimators expected value and the true value of the parameter being estimated while *variance* is the expected squared difference between an estimator and its expected value. So if θ ^ is an estimator of some unknown parameter θ, then Bias ( θ ^ ) \= E \[ θ ^ \] − θ while Var ( θ ^ ) \= E \[ ( θ ^ − E \[ θ ^ \] ) 2 \]. A bias of zero means that an estimator is *correctly centered*: its expectation equals the truth. We say that such an estimator is *unbiased*.[2](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn2) A small variance means that an estimator is *precise*: it doesn’t “jump around” too much. Ideally we’d like an estimator that is correctly centered and precise. But it turns out that there is generally a *trade-off* between bias and variance: if you want to reduce one of them, you have to accept an increase in the other.
A common way of trading off bias and variance relies on a concept called *mean-squared error* (MSE) defined as the *sum* of the squared bias and the variance.[3](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn3) In particular: MSE ( θ ^ ) \= Var ( θ ^ ) \+ Bias ( θ ^ ) 2. Equivalently, we can write MSE ( θ ^ ) \= E \[ ( θ ^ − θ ) 2 \].[4](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn4) To borrow some terminology from introductory microeconomics, you can think of MSE as the *negative* of a utility function over bias and variance. Both bias and variance are “bads” in that we’d rather have less rather than more of each. This formula expresses our *preferences* in terms of how much of one we’d be willing to accept in exchange for less of the other. Slightly foreshadowing something that will come later in this post, we can think of MSE as the square of the average distance that an archer’s arrows land from the bulls-eye. Smaller values of MSE are better: variance measures how closely the arrows cluster together while bias measures how far the center of the cluster is from the bulls-eye, as in the following diagram:

### A Shrinkage Estimator
Returning to our maximum likelihood estimator: it’s unbiased, Bias ( μ ^ ML ) \= 0, so MSE ( μ ^ ML ) \= Var ( μ ^ ML ) \= 1. Suppose that low MSE is what we’re after. Is there any way to improve on the ML estimator? In other words, can we achieve an MSE that’s lower than one? The answer turns out to be *yes*. Here’s the idea. Suppose we had some reason to believe that the true mean μ isn’t very large. Then perhaps we could try to adjust our maximum likelihood estimate by *shrinking* slightly towards zero. One way to do this would be by taking a weighted average of the ML estimator and zero: μ ^ ( λ ) \= ( 1 − λ ) × μ ^ ML \+ λ × 0 \= ( 1 − λ ) X for 0 ≤ λ ≤ 1. The constant ( 1 − λ ) is called the “shrinkage factor” and controls how the ML estimator gets pulled towards zero.[5](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn5) We get a different estimator for every value of λ. If λ \= 0 then we get the ML estimator back. If λ \= 1 then we get a very silly estimator that ignores the data and simply reports zero no matter what! So let’s see how the MSE depends on our choice of λ. Substituting the definition of μ ^ ( λ ) into the formulas for bias and variance gives: Bias \[ μ ^ ( λ ) \] \= E \[ ( 1 − λ ) μ ^ ML \] − μ \= ( 1 − λ ) E \[ μ ^ ML \] − μ \= ( 1 − λ ) μ − μ \= − λ μ Var \[ μ ^ ( λ ) \] \= Var \[ ( 1 − λ ) μ ^ ML \] \= ( 1 − λ ) 2 Var \[ μ ^ ML \] \= ( 1 − λ ) 2 MSE \[ μ ^ ( λ ) \] \= Var \[ μ ^ ( λ ) \] \+ Bias \[ μ ^ ( λ ) \] 2 \= ( 1 − λ ) 2 \+ λ 2 μ 2 Unless λ \= 0, the shrinkage estimator is *biased*. And while the MSE of the ML estimator is always one, regardless of the true value of μ, the MSE of the shrinkage estimator *depends on the unknown parameter* μ.
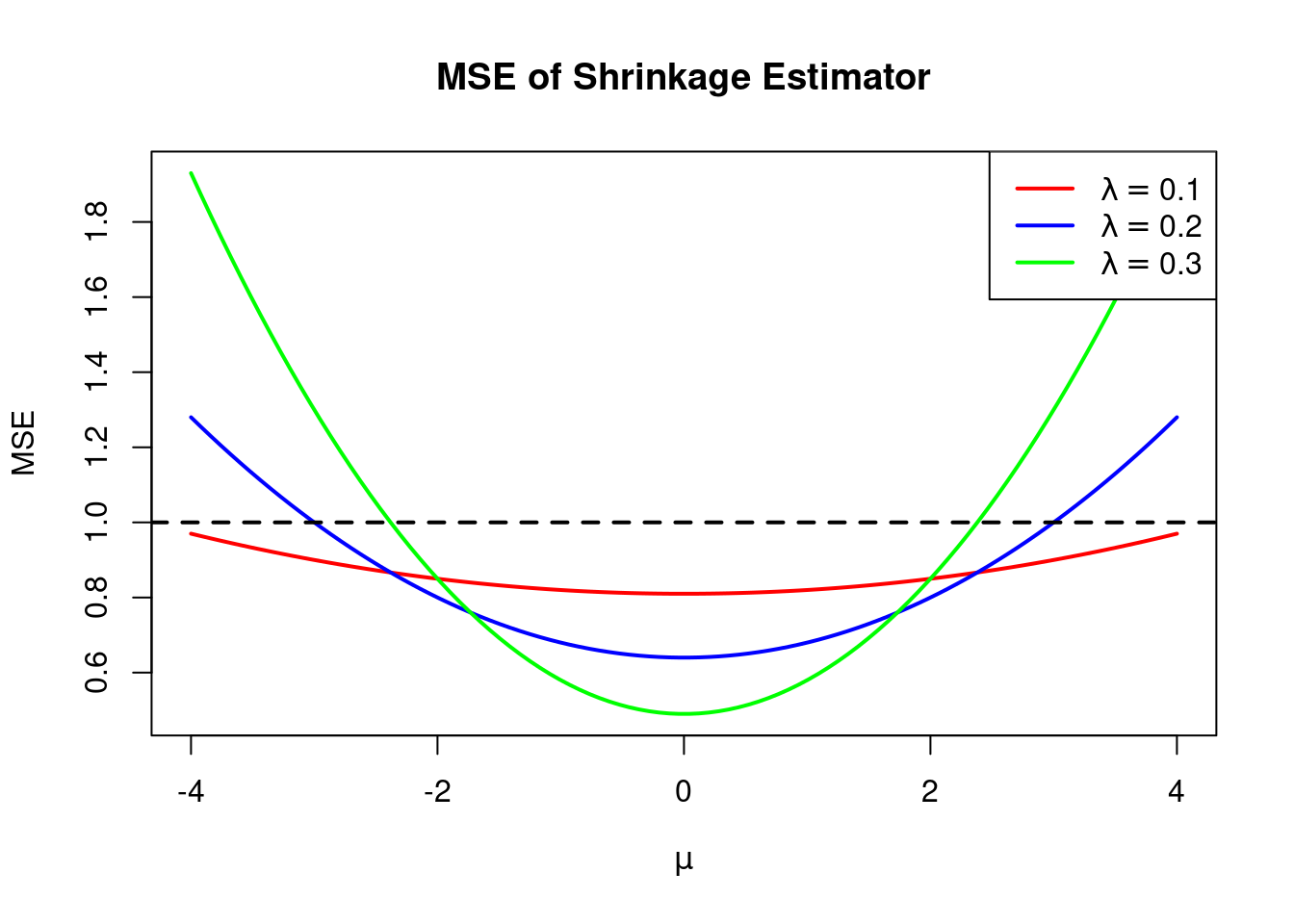
So why should we use a biased estimator? The answer is that by tolerating a small amount of bias we may be able to achieve a *larger* reduction in variance, resulting in a lower MSE compared to the higher variance but unbiased ML estimator. A quick plot shows us that the shrinkage estimator *can indeed* have a lower MSE than the ML estimator depending on the value of λ and the true value of μ:
```
# Range of values for the unknown parameter mu
mu <- seq(-4, 4, length = 100)
# Try three different values of lambda
lambda1 <- 0.1
lambda2 <- 0.2
lambda3 <- 0.3
# Plot the MSE of the shrinkage estimator as a function of mu for all
# three values of lambda at once
matplot(mu, cbind((1 - lambda1)^2 + lambda1^2 * mu^2,
(1 - lambda2)^2 + lambda2^2 * mu^2,
(1 - lambda3)^2 + lambda3^2 * mu^2),
type = 'l', lty = 1, lwd = 2,
col = c('red', 'blue', 'green'),
xlab = expression(mu), ylab = 'MSE',
main = 'MSE of Shrinkage Estimator')
# Add legend
legend('topright', legend = c(expression(lambda == 0.1),
expression(lambda == 0.2),
expression(lambda == 0.3)),
col = c('red', 'blue', 'green'), lty = 1, lwd = 2)
# Add dashed line for MSE of ML estimator
abline(h = 1, lty = 2, lwd = 2)
```
### Some Algebra
It’s time for some algebra. If you’re tempted to skip this *please don’t*: this section is a warm-up for our main event. If you thoroughly understand the mechanics of shrinkage in this simple example, everything that follows below will seem much more natural.
As seen from the plot above, the MSE of our shrinkage estimator (the solid lines) is lower than that of the ML estimator (the dashed line) provided that our chosen value of λ isn’t too large relative to the true value of μ. With a bit of algebra, we can work out *precisely* how large λ can be to make shrinkage worthwhile. Since MSE \[ μ ^ ML \] \= 1, by expanding and simplifying the expression for MSE \[ μ ^ ( λ ) \] we see that MSE \[ μ ^ ( λ ) \] \< MSE \[ μ ^ ML \] if and only if ( 1 − λ ) 2 \+ λ 2 μ 2 \< 1 1 − 2 λ \+ λ 2 \+ λ 2 μ 2 \< 1 λ 2 ( 1 \+ μ 2 ) − 2 λ \< 0 λ \[ λ ( 1 \+ μ 2 ) − 2 \] \< 0\. Since λ ≥ 0, the final inequality can only hold if the factor inside the square brackets is negative, i.e. λ ( 1 \+ μ 2 ) − 2 \< 0 λ \< 2 1 \+ μ 2 . This shows that any choice of λ between 0 and 2 / ( 1 \+ μ 2 ) will give us a shrinkage estimator with an MSE less than one. To check our algebra, we can change the inequality to an equality and solve for μ to obtain the boundary of the region where shrinkage is better than ML: λ ( 1 \+ μ 2 ) − 2 \= 0 1 \+ μ 2 \= 2 / λ μ \= ± 2 / λ − 1 . Adding these boundaries to a simplified version of our previous plot with only λ \= 0\.3 we see that everything works out correctly: the dashed red lines intersect the blue curve at the points where the MSE of the shrinkage estimator equals that of the ML estimator.
```
# Plot the MSE of the shrinkage estimator as a function of mu for lambda = 0.3
lambda <- 0.3
plot(mu, (1 - lambda)^2 + lambda^2 * mu^2, type = 'l', lty = 1, lwd = 2,
col = 'blue', xlab = expression(mu), ylab = 'MSE',
main = 'Boundary of Region Where Shrinkage is Better than ML')
# Add dashed line for MSE of ML estimator
abline(h = 1, lty = 2, lwd = 2)
# Add boundaries of region where shrinkage is better than ML estimator
abline(v = c(sqrt(2/lambda - 1), -sqrt(2/lambda - 1)), lty = 3, lwd = 2,
col = 'red')
```
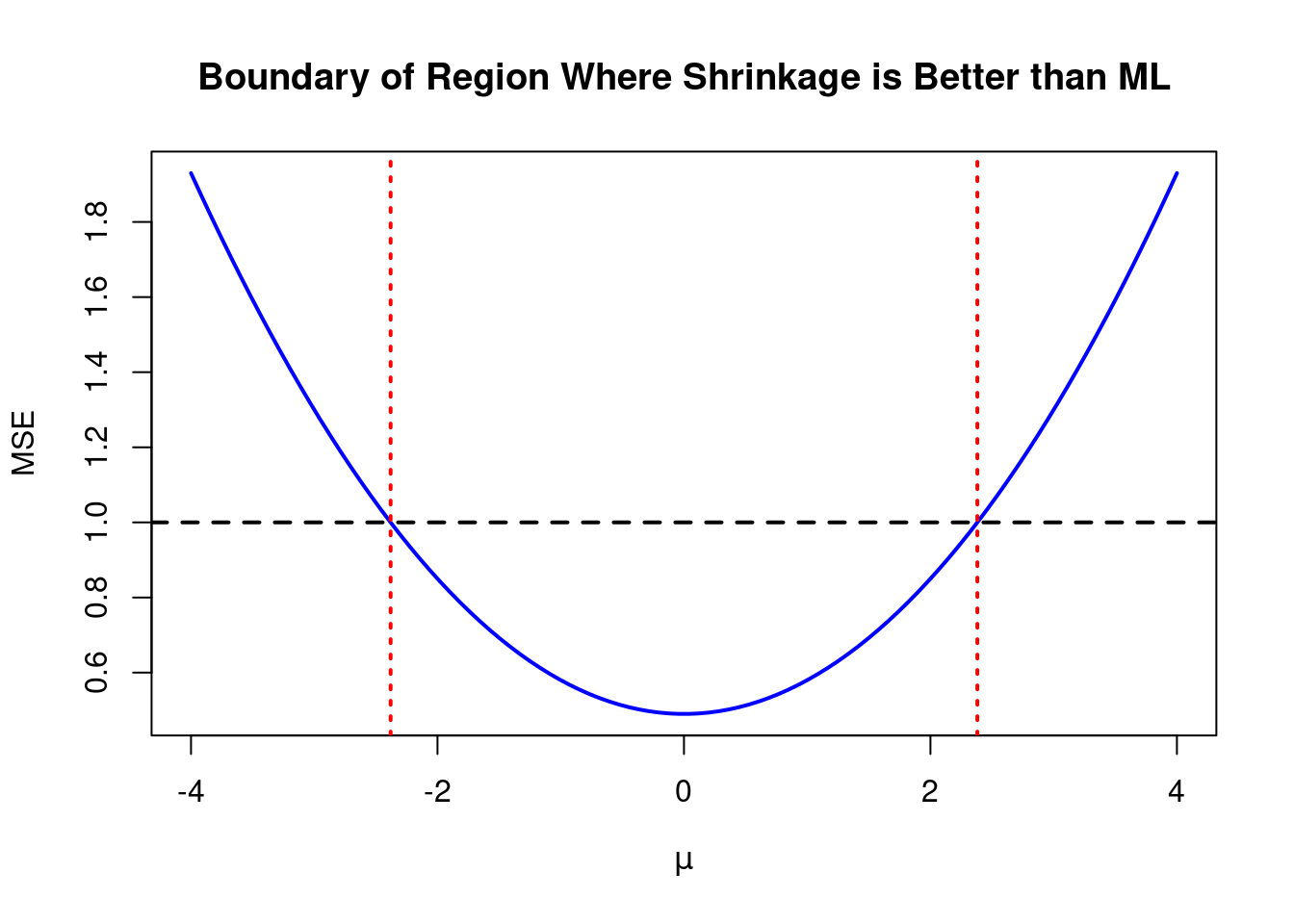
But there’s still more to learn! Suppose we wanted to take things *one step further* and find the *optimal* value of λ for any given value of μ. In other words, suppose we wanted the value of λ that *minimizes* the MSE of our shrinkage estimator given a particular assumed value for μ. Since MSE \[ μ ^ ( λ ) \] is a quadratic function of λ, as shown above, this turns out to be a fairly straightforward calculation. Differentiating, d d λ MSE \[ μ ^ ( λ ) \] \= d d λ \[ ( 1 − λ ) 2 \+ λ 2 μ 2 \] \= − 2 ( 1 − λ ) \+ 2 λ μ 2 \= 2 \[ λ ( 1 \+ μ 2 ) − 1 \] d 2 d λ 2 MSE \[ μ ^ ( λ ) \] \= 2 ( 1 \+ μ 2 ) \> 0 so there is a unique global minimum at λ ∗ ≡ 1 / ( 1 \+ μ 2 ). This gives the *optimal* shrinkage factor in the sense that it minimizes the MSE of the shrinkage estimator. Substituting λ ∗ into the expression for MSE \[ μ ^ ( λ ) \] gives: MSE \[ μ ^ ( λ ∗ ) \] \= ( 1 − 1 1 \+ μ 2 ) 2 \+ ( 1 1 \+ μ 2 ) 2 μ 2 \= ( μ 2 1 \+ μ 2 ) 2 \+ ( 1 1 \+ μ 2 ) 2 μ 2 \= ( 1 1 \+ μ 2 ) 2 ( μ 4 \+ μ 2 ) \= ( 1 1 \+ μ 2 ) 2 μ 2 ( 1 \+ μ 2 ) \= μ 2 1 \+ μ 2 \< 1\.
## Stein’s Paradox
### Recap
We’re moments away from having all the ingredients we need to introduce Stein’s Paradox! But first let’s review what we’ve uncovered thus far. We’ve seen that the shrinkage estimator can improve on the ML estimator in terms of MSE provided that λ is chosen judiciously: it needs to be between zero and 2 / ( 1 \+ μ 2 ). The optimal choice of λ, namely λ ∗ \= 1 / ( 1 \+ μ 2 ), gives an MSE of μ 2 / ( 1 \+ μ 2 ). This is always lower than one, the MSE of the ML estimator.
There’s just one massive problem we’ve ignored this whole time: **we don’t know the value of** μ! As seen from the figure plotted above, the MSE curves for different values of λ *cross each other*: the best one to use depends on the true value of μ. This doesn’t mean that all is lost. Perhaps in practice we have some outside information about the likely value of μ that could help guide our choice of λ. What it does mean is that there’s no “one-size-fits-all” value.
### Admissibility
It’s time to introduce a bit of technical vocabulary. We say that an estimator θ ~ **dominates** another estimator θ ^ if MSE \[ θ ~ \] ≤ MSE \[ θ ^ \] for *all* possible values of the parameter θ being estimated and MSE \[ θ ~ \] \< MSE \[ θ ^ \] for at least *one* possible value of θ.[6](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn6) In words, this means that it never makes sense to use θ ^ in preference to θ ~. No matter what the true parameter value is, you can’t do worse with θ ~ and you might do better. An estimator that is *not dominated* by any other estimator is called **admissible**; an estimator that *is dominated* by some other estimator is called **inadmissible**. The concept of *admissibility* in decision theory is a bit like the concept of [Pareto efficiency](https://en.wikipedia.org/wiki/Pareto_efficiency) in microeconomics. An admissible estimator is only “good” in the sense that it doesn’t leave any money on the table: there’s no way to do better for one parameter value without doing worse for another. In a similar way, a Pareto efficient allocation in economics is one in which no individual can be made better off without making another person worse off.
It’s quite challenging to prove, but in fact the ML estimator θ ^ M L \= X turns out to be admissible in our little example. So while we could potentially do better by using shrinkage, it’s not a slam-dunk case. If we really have no idea of how large μ is likely to be, the ML estimator is a reasonable choice. Because it’s admissible, at the very least we know that there’s no free lunch\!
### A More General Example
Now let’s make things a bit more interesting. For the rest of this post, suppose that we observe not a single draw X from a Normal ( μ , 1 ) distribution but a *collection* of p independent draws from p *different* normal distributions: X 1 , X 2 , . . . , X p ∼ independent Normal ( μ j , 1 ) , j \= 1 , . . . , p . You can think of this as p copies of our original problem: we observe X j ∼ Normal ( μ j , 1 ) and our task is to estimate μ j. The observations are all independent, and each comes from a distribution with a potentially **different mean**. At first glance it seems like these p separate problems should have *absolutely nothing to do with each other*. And indeed the maximum likelihood estimator for the collection of p means is simply μ ^ ML ( j ) \= X j. As above in our example with p \= 1, the question is: how good is the ML estimator, and can we do any better?
### Composite MSE
But first things first: how can we evaluate the quality of p estimators for p different parameters *at the same time*? A common approach, and the one we will follow here, is to take the *sum* of the individual MSEs of each estimator, yielding a quantity called **composite MSE**. If μ ^ 1 , μ ^ 2 , … , μ ^ p is a collection of estimators for each of the individual unknown means, then the composite MSE is defined as Composite MSE ≡ ∑ j \= 1 p MSE ( μ ^ j ) \= ∑ j \= 1 p \[ Bias ( μ ^ j ) 2 \+ Var ( μ ^ j ) \] \= ∑ j \= 1 p E \[ ( μ ^ j − μ j ) 2 \] . Adopting composite MSE as our measure of *good* performance means that we view each of the p estimation problems as in some way “interchangeable”–we’re happy to accept a trade in which we do a slightly worse job estimating μ j in exchange for doing a much better job estimating μ k. At the end of the post I’ll say a few more words about this idea and when it may or may not be reasonable. But for the rest of the post, we will assume that our goal is to **minimize the composite MSE**. The concept of composite MSE will be crucial in understanding why the James-Stein estimator works the way it does.
### Stein’s Paradox
Putting our new idea into practice, we see that the composite MSE of the ML estimator is p regardless of the true values of the individual means μ 1 , … , μ p since ∑ j \= 1 p MSE \[ μ ^ ML ( j ) \] \= ∑ j \= 1 p MSE ( X j ) \= ∑ j \= 1 p Var ( X j ) \= p . If the ML estimator is admissible, then there should be no other estimator that always has an MSE less than or equal to p and sometimes has an MSE strictly less than p. I’ve already told you that this is true when p \= 1. When p \= 2 it’s still true: the ML estimator remains admissible. But when p ≥ 3 something very unexpected happens: it becomes possible to construct an estimator that **dominates** the ML estimator by using information from *all* of the ( X 1 , . . . , X p ) observations to estimate μ j. This is spite of the fact that there is *no obvious connection* between the observations. Again: they are all independent and come from distributions with different means\!
The estimator that does the trick is the so-called “James-Stein Estimator” (JS), defined according to μ ^ JS ( j ) \= ( 1 − p − 2 ∑ k \= 1 p X k 2 ) X j . This estimator dominates the ML estimator when p ≥ 3 in that
∑ j \= 1 p MSE \[ μ ^ JS ( j ) \] ≤ ∑ j \= 1 p MSE \[ μ ^ ML ( j ) \] \= p for *all* possible values of the p unknown means μ j with strict inequality for at least *some* values. Taking a closer look at the formula, we see that the James-Stein estimator is just a *shrinkage* estimator applied to each of the p means, namely μ ^ JS ( j ) \= ( 1 − λ ^ JS ) X j , λ ^ JS ≡ p − 2 ∑ k \= 1 p X k 2 . The shrinkage factor in the James-Stein estimator depends on the number of means we’re estimating, p, along with the *overall* sum of the squared observations. All else equal, the more parameters we need to estimate, the more we shrink each of them towards zero. And the farther the observations are from zero *overall*, the less we shrink *each of them* towards zero.
Just like our simple shrinkage estimator from above, the James-Stein estimator achieves a lower MSE by tolerating a small bias in exchange for a larger reduction in variance, compared to the higher-variance but unbiased ML estimator. Unlike our simple shrinkage estimator, the James-Stein estimator uses the *data* to determine the shrinkage factor. And as long as p ≥ 3 it is always *at least as good* as the ML estimator and sometimes *much better*. The **paradox** is that this seems impossible: how can information from *all* of the observations be useful when they come from *different* distributions with no obvious connection?
The rest of this post will *not* prove that the James-Stein estimator dominates the ML estimator. Instead it will try to convince you that there is some *very good intuition* for why the formula for the James-Stein estimator takes the form it does. By the end, I hope you’ll feel that, far from seeming paradoxical, using *all* of the observations to determine the shrinkage factor for one particular μ j makes perfect sense.
## Where does the James-Stein Estimator Come From?
### An Infeasible Estimator When p \= 2
To start the ball rolling, let’s [assume a can-opener](https://en.wikipedia.org/wiki/Assume_a_can_opener): suppose that we don’t know any of the *individual* means μ j but for some strange reason a benevolent deity has told us the value of their sum of squares: c 2 ≡ ∑ j \= 1 p μ j 2 . It turns out that this is enough information to construct a shrinkage estimator that *always* has a lower composite MSE than the ML estimator. Let’s see why this is the case. If p \= 1, then telling you c 2 is the same as telling you μ 2. Granted, knowledge of μ 2 isn’t as informative as knowledge of μ. For example, if I told you that μ 2 \= 9 you couldn’t tell whether μ \= 3 or μ \= − 3. But, as we showed above, the optimal shrinkage estimator when p \= 1 sets λ ∗ \= 1 / ( 1 \+ μ 2 ) and yields an MSE of μ 2 / ( 1 \+ μ 2 ) \< 1. Since λ ∗ only depends on μ through μ 2, we’ve *already shown* that knowledge of c 2 allows us to construct a shrinkage estimator that dominates the ML estimator when p \= 1.
So what if p equals 2? In this case, knowledge of c 2 \= μ 1 2 \+ μ 2 2 is equivalent to knowing the *radius* of a circle centered at the origin in the ( μ 1 , μ 2 ) plane where the two unknown means must lie. For example, if I told you that c 2 \= 1 you would know that ( μ 1 , μ 2 ) lies somewhere on a circle of radius one centered at the origin. As illustrated in the following plot, the points ( x 1 , x 2 ) and ( y 1 , y 2 ) would then be potential values of ( μ 1 , μ 2 ) as would all other points on the blue circle.
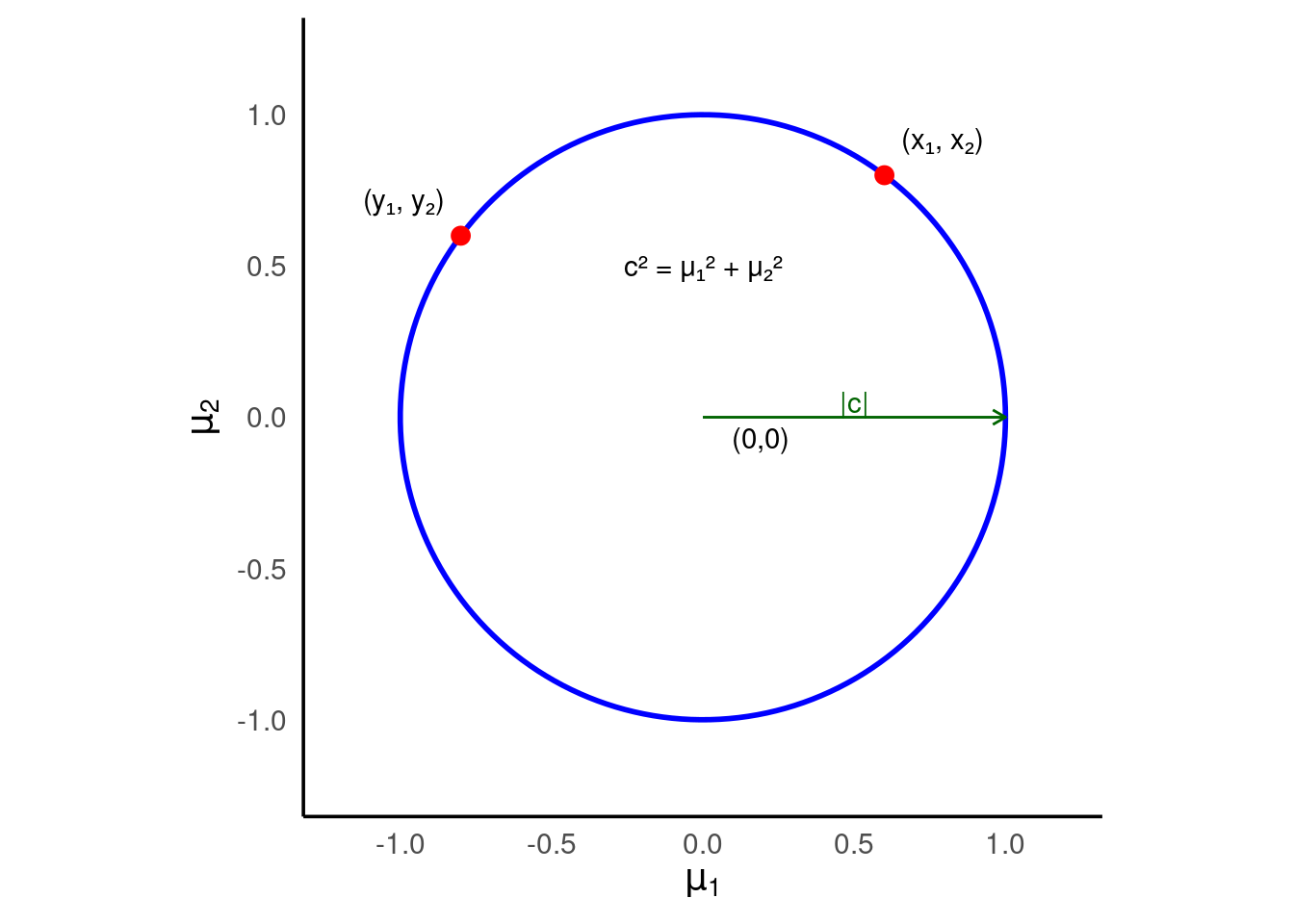
So how can we construct a shrinkage estimator of ( μ 1 , μ 2 ) with lower composite MSE than the ML estimator if c 2 is known? While there are other possibilities, the simplest would be to use the *same* shrinkage factor for each of the two coordinates. In other words, our estimator would be μ ^ 1 ( λ ) \= ( 1 − λ ) X 1 , μ ^ 2 ( λ ) \= ( 1 − λ ) X 2 for some λ between zero and one. The composite MSE of this estimator is just the sum of the MSE of each *individual* component, so we can re-use our algebra from above to obtain MSE \[ μ ^ 1 ( λ ) \] \+ MSE \[ μ ^ 2 ( λ ) \] \= \[ ( 1 − λ ) 2 \+ λ 2 μ 1 2 \] \+ \[ ( 1 − λ ) 2 \+ λ 2 μ 2 2 \] \= 2 ( 1 − λ ) 2 \+ λ 2 ( μ 1 2 \+ μ 2 2 ) \= 2 ( 1 − λ ) 2 \+ λ 2 c 2 . Notice that the composite MSE only depends on ( μ 1 , μ 2 ) through their sum of squares, c 2. Differentiating with respect to λ, just as we did above in the p \= 1 case, d d λ \[ 2 ( 1 − λ ) 2 \+ λ 2 c 2 \] \= − 4 ( 1 − λ ) \+ 2 λ c 2 \= 2 \[ λ ( 2 \+ c 2 ) − 2 \] d 2 d λ 2 \[ 2 ( 1 − λ ) 2 \+ λ 2 c 2 \] \= 2 ( 2 \+ c 2 ) \> 0 so there is a unique global minimum at λ ∗ \= 2 / ( 2 \+ c 2 ). Substituting this value of λ into the expression for the composite MSE, a few lines of algebra give MSE \[ μ ^ 1 ( λ ∗ ) \] \+ MSE \[ μ ^ 2 ( λ ∗ ) \] \= 2 ( 1 − 2 2 \+ c 2 ) 2 \+ ( 2 2 \+ c 2 ) 2 c 2 \= 2 ( c 2 2 \+ c 2 ) . Since c 2 / ( 2 \+ c 2 ) \< 1 for all c 2 \> 0, the optimal shrinkage estimator *always* has a composite MSE less than 2, the composite MSE of the ML estimator. Strictly speaking this estimator is **infeasible** since we don’t know c 2. But it’s a crucial step on our journey to make the leap from applying shrinkage to an estimator for a *single* unknown mean, to using the same idea for *more than one* unknown mean.
### A Simulation Experiment for p \= 2
You may have already noticed that it’s easy to generalize this argument to p \> 2. But before we consider the general case, let’s take a moment to understand the geometry of shrinkage estimation for p \= 2 a bit more deeply. The nice thing about two-dimensional problems is that they’re easy to plot. So here’s a graphical representation of both the ML estimator and our infeasible optimum shrinkage estimator when p \= 2. I’ve set the true, unknown, values of μ 1 and μ 2 to one so the true value of c 2 is 2 and the optimal choice of λ is λ ∗ \= 2 / ( 2 \+ c 2 ) \= 2 / 4 \= 0\.5. The following R code simulates our estimators and visualizes their performance, helping us see the shrinkage effect in action.
```
set.seed(1983)
nreps <- 50
mu1 <- mu2 <- 1
x1 <- mu1 + rnorm(nreps)
x2 <- mu2 + rnorm(nreps)
csq <- mu1^2 + mu2^2
lambda <- csq / (2 + csq)
par(mfrow = c(1, 2))
# Left panel: ML Estimator
plot(x1, x2, main = 'MLE', pch = 20, col = 'black', cex = 2,
xlab = expression(mu[1]), ylab = expression(mu[2]))
abline(v = mu1, lty = 1, col = 'red', lwd = 2)
abline(h = mu2, lty = 1, col = 'red', lwd = 2)
# Add MSE to the plot
text(x = 2, y = 3, labels = paste("MSE =",
round(mean((x1 - mu1)^2 + (x2 - mu2)^2), 2)))
# Right panel: Shrinkage Estimator
plot(x1, x2, main = 'Shrinkage', xlab = expression(mu[1]),
ylab = expression(mu[2]))
points(lambda * x1, lambda * x2, pch = 20, col = 'blue', cex = 2)
segments(x0 = x1, y0 = x2, x1 = lambda * x1, y1 = lambda * x2, lty = 2)
abline(v = mu1, lty = 1, col = 'red', lwd = 2)
abline(h = mu2, lty = 1, col = 'red', lwd = 2)
abline(v = 0, lty = 1, lwd = 2)
abline(h = 0, lty = 1, lwd = 2)
# Add MSE to the plot
text(x = 2, y = 3, labels = paste("MSE =",
round(mean((lambda * x1 - mu1)^2 +
(lambda * x2 - mu2)^2), 2)))
```
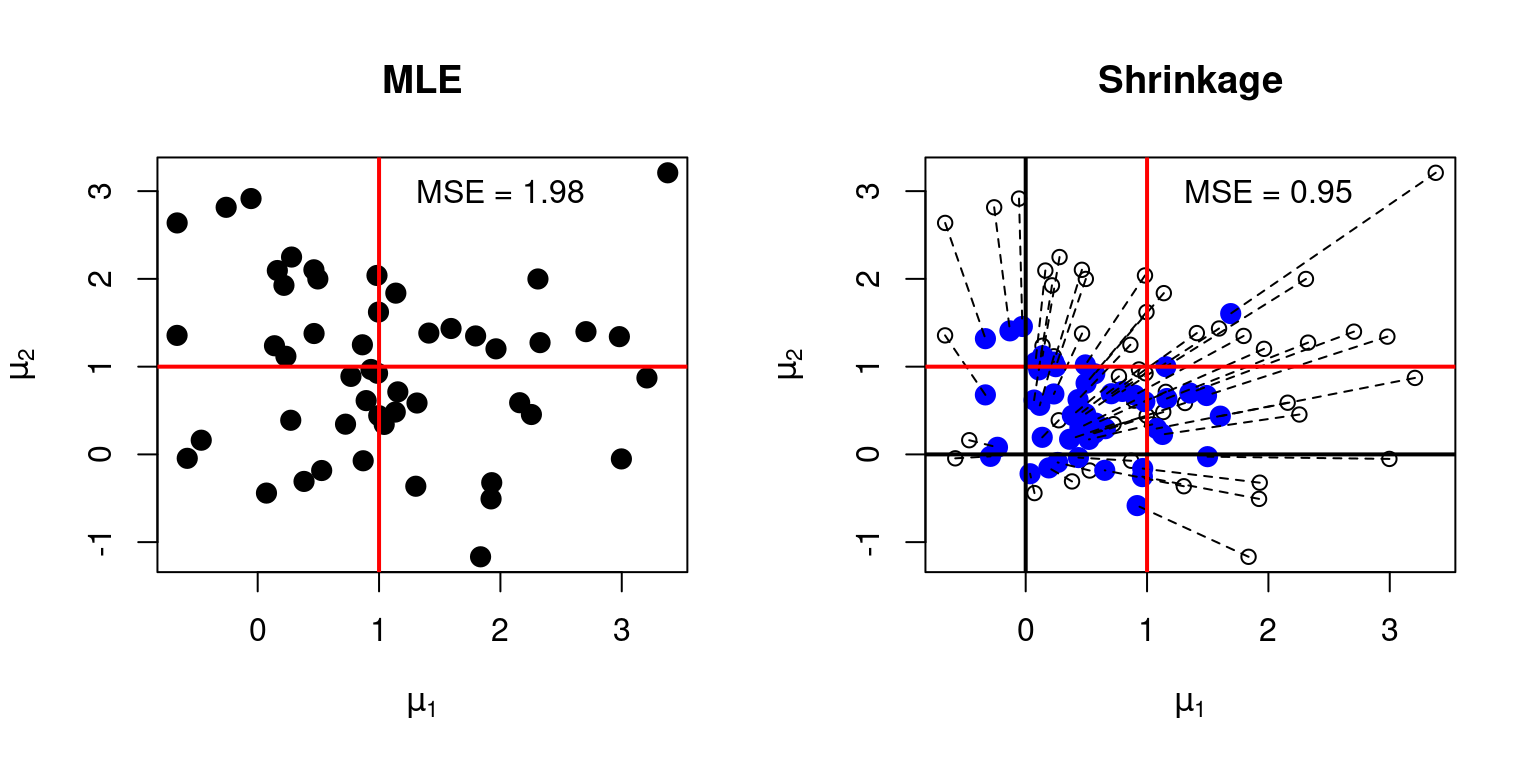
My plot has two panels. The left panel shows the raw data. Each black point is a pair ( X 1 , X 2 ) of independent normal draws with means ( μ 1 \= 1 , μ 2 \= 1 ) and variances ( 1 , 1 ). As such, each point is also the *ML estimate* (MLE) of ( μ 1 , μ 2 ) based on ( X 1 , X 2 ). The red cross shows the location of the true values of ( μ 1 , μ 2 ), namely ( 1 , 1 ). There are 50 points in the plot, representing 50 replications of the simulation, each independent of the rest and with the same parameter values. This allows us to measure how close the ML estimator is to the true value of ( μ 1 , μ 2 ) in repeated sampling, approximating the composite MSE.
The right panel is more complicated. This shows *both* the ML estimates (unfilled black circles) *and* the corresponding shrinkage estimates (filled blue circles) along with dashed lines connecting them. Each shrinkage estimate is constructed by “pulling” the corresponding MLE towards the origin by a factor of λ \= 0\.5. Thus, if a given unfilled black circle is located at ( X 1 , X 2 ), the corresponding filled blue circle is located at ( 0\.5 X 1 , 0\.5 X 2 ). As in the left panel, the red cross in the right panel shows the true values of ( μ 1 , μ 2 ), namely ( 1 , 1 ). The black cross, on the other hand, shows the point towards which the shrinkage estimator pulls the ML estimator, namely ( 0 , 0 ).
We see immediately that the ML estimator is *unbiased*: the black filled dots in the left panel (along with the unfilled ones in the right) are centered at ( 1 , 1 ). But the ML estimator is also *high-variance*: the black dots are quite spread out around ( 1 , 1 ). We can approximate the composite MSE of the ML estimator by computing the average squared Euclidean distance between the black points and the red cross.[7](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn7) And in keeping with our theoretical calculations, the simulation gives a composite MSE of almost exactly 2 for the ML estimator.
In contrast, the optimal shrinkage estimator is *biased*: the filled blue dots in the right panel centered somewhere between the red cross (the true means) and the origin. But the shrinkage estimator also has a lower variance: the filled blue dots are much closer together than the black ones. Even more importantly *they are on average closer to* ( μ 1 , μ 2 ), as indicated by the red cross and as measured by composite MSE. Our theoretical calculations showed that the composite MSE of the optimal shrinkage estimator equals 2 c 2 / ( 2 \+ c 2 ). When c 2 \= 2, as in this case, we obtain 2 × 2 / ( 2 \+ 2 ) \= 1. Again, this is almost exactly what we see in the simulation.
If we had used more than 50 simulation replications, the composite MSE values would have been even closer to our theoretical predictions, at the cost of making the plot much harder to read! But I hope the key point is still clear: shrinkage *pulls* the MLE towards the origin, and can give a *much* lower composite MSE.
### An Infeasible Estimator: The General Case
Now that we understand the case of p \= 2, the general case is a snap. Our shrinkage estimator of each μ j will take the form μ ^ j ( λ ) \= ( 1 − λ ) X j , j \= 1 , … , p for some λ between zero and one. To find the optimal choice of λ, we minimize ∑ j \= 1 p MSE \[ μ ^ j ( λ ) \] \= ∑ j \= 1 p \[ ( 1 − λ ) 2 \+ λ 2 μ j 2 \] \= p ( 1 − λ ) 2 \+ λ 2 c 2 with respect to λ. Again, the key is that the composite MSE only depends on the unknown means through c 2. Using almost exactly the same calculations as above for the case of p \= 2, we find that λ ∗ \= p p \+ c 2 , ∑ j \= 1 p MSE \[ μ ^ j ( λ ∗ ) \] \= p ( c 2 p \+ c 2 ) . since c 2 / ( p \+ c 2 ) \< 1 for all c 2 \> 0, the optimal shrinkage estimator *always* has a composite MSE less than p, the composite MSE of the ML estimator.
### Not Quite the James-Stein Estimator
The end is in sight! We’ve shown that if we knew the sum of squares of the unknown means, c 2, we could construct a shrinkage estimator that always has a lower composite MSE than the ML estimator. But we don’t know c 2. So what can we do? To start off, re-write λ ∗ as follows λ ∗ \= p p \+ c 2 \= 1 1 \+ c 2 / p . This way of writing things makes it clear that it’s not c 2 *per se* that matters but rather c 2 / p. And this quantity is simply is the *average* of the unknown squared means: c 2 p \= 1 p ∑ j \= 1 p μ j 2 . So how could we learn c 2 / p? An idea that immediately suggests itself is to estimate this quantity by replacing each unobserved μ j with the corresponding observation X j, in other words 1 p ∑ j \= 1 p X j 2 . This is a good starting point, but we can do better. Since X j ∼ Normal ( μ j , 1 ), we see that E \[ 1 p ∑ j \= 1 p X j 2 \] \= 1 p ∑ j \= 1 p E \[ X j 2 \] \= 1 p ∑ j \= 1 p \[ Var ( X j ) \+ E ( X j ) 2 \] \= 1 p ∑ j \= 1 p ( 1 \+ μ j 2 ) \= 1 \+ c 2 p . This means that ( ∑ j \= 1 p X j 2 ) / p will on average *overestimate* c 2 / p by one. But that’s a problem that’s easy to fix: simply subtract one! This is a rare situation in which there is *no bias-variance tradeoff*. Subtracting a constant, in this case one, doesn’t contribute any additional variation while completely removing the bias. Plugging into our formula for λ ∗, this suggests using the estimator λ ^ ≡ 1 1 \+ \[ ( 1 p ∑ j \= 1 p X j 2 ) − 1 \] \= 1 1 p ∑ j \= 1 p X j 2 \= p ∑ j \= 1 p X j 2 as our stand-in for the unknown λ ∗, yielding a shrinkage estimator that I’ll call “NQ” for “not quite” for reasons that will become apparent in a moment: μ ^ NQ ( j ) \= ( 1 − p ∑ k \= 1 p X k 2 ) X j . Notice what’s happening here: our optimal shrinkage estimator depends on c 2 / p, something we can’t observe. But we’ve constructed an *unbiased estimator* of this quantity by using *all of the observations* X j. This is the resolution of the paradox discussed above: all of the observations contain information about c 2 since this is simply the sum of the squared means. And because we’ve chosen to minimize composite MSE, the optimal shrinkage factor only depends on the individual μ j parameters through c 2! This is the sense in which it’s possible to learn something useful about, say, μ 1 from X 2 in spite of the fact that E \[ X 2 \] \= μ 2 may bear no relationship to μ 1.
But wait a minute! This looks *suspiciously familiar*. Recall that the James-Stein estimator is given by μ ^ JS ( j ) \= ( 1 − p − 2 ∑ k \= 1 p X k 2 ) X j . Just like the JS estimator, my NQ estimator shrinks each of the p means towards zero by a factor that depends on the number of means we’re estimating, p, and the overall sum of the squared observations. The key difference between JS and NQ is that JS uses p − 2 in the numerator instead of p. This means that NQ is a more “aggressive” shrinkage estimator than JS: it pulls the means towards zero by a larger amount than JS. This difference turns out to be crucial for proving that the JS estimator dominates the ML estimator. But when it comes to understanding why the JS estimator has the *form* that it does, I would argue that the difference is minor. If you want all the gory details of where that extra − 2 comes from, along with the closely related issue of why p ≥ 3 is crucial for JS to dominate the ML estimator, see [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) or [section 7.3](https://ditraglia.com/econ722/main.pdf) from my Econ 722 teaching materials.
## Conclusion
Before we conclude, there’s one important caveat to bear in mind. In addition to the qualifications that NQ isn’t *quite* JS, and that JS only dominates the MLE when p ≥ 3, there’s one more fundamental issue that could be easily missed. Our decision to minimize *composite* MSE is *absolutely crucial* to the reasoning given above. The magic of shrinkage depends on our willingness to accept a trade-off in which we do a worse job estimating one mean in exchange for doing a better job estimating another, as composite MSE imposes. Whether this makes sense in practice depends on the context.
If we’re searching for a lost submarine in the ocean (a 3-dimensional problem), it makes perfect sense to be willing to be farther from the submarine in one dimension in exchange for being closer in another. That’s because *Euclidean distance* is obviously what we’re after here. But if instead we’re estimating [teacher value-added](https://ideas.repec.org/p/nbr/nberwo/27094.html) and the results of our estimation exercise will be used to determine which teachers lose their jobs, it’s less clear that we should be willing to be farther from one teacher in exchange for being closer to another. Certainly that would be no consolation to someone who had been wrongly dismissed! If we were merely using this information to identify teachers who might need extra help, it’s another story. But the point I’m trying to make here is that our choice of which criterion to minimize necessarily encodes our *values* in a particular problem.
But with that said, I hope you’re satisfied that this extremely long post was worth the effort. Without using any fancy mathematics or statistical theory, we’ve managed to invent something that is *nearly identical* to the James-Stein estimator and thus to resolve Stein’s paradox. We started by pretending what we knew c 2 and showed that this would allow us to derive a shrinkage estimator with a lower composite MSE than the ML estimator. Then we simply plugged in an unbiased estimator of the key unknown quantity: c 2 / p. Because all the observations contain information about c 2, it makes sense that we should decide how much to shrink one component X j by using all of the others. At this point, I hope that the James-Stein estimator seems not only plausible but practically *obvious*, excepting of course that pesky − 2 in the numerator.
## Footnotes
1. If I ruled the universe, the Gauss-Markov Theorem would be demoted to much less exalted status in econometrics teaching\
2. Don’t let words do your thinking for you: “bias” sounds like a very bad thing, like kicking puppies. But that’s because the word “bias” has a negative connotation in English. In statistics, it’s just a technical term for “not centered”. An estimator can be biased and still be very good. Indeed the punchline of this post is that the James-Stein estimator is biased but can be much better than the obvious alternative\
3. Why squared bias and not simply bias itself? The answer is units: bias is measured in the same units as the parameter being estimated while the variance is in squared units. It doesn’t make sense to add things with different units, so we either have to square the bias or take the square root of the variance, i.e. replace it with the standard deviation. But bias can be negative, and we wouldn’t want a large negative bias to cancel out a large standard deviation so MSE squares the bias instead.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref3)
4. See if you can prove this as a homework exercise\
5. In Bayesian terms, we could view this “shrinkage” idea as calculating the posterior mean of μ conditional on our data X under a normal prior. In this case λ would equal τ / ( 1 \+ τ ) where τ is the *prior precision*, i.e. the reciprocal of the prior variance. But for this post we’ll mainly stick to the Frequentist perspective.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref5)
6. Strictly speaking all of this pre-supposes that we’re working with squared-error loss so that MSE is the right thing to minimize. There are other loss functions we could have used instead and these would lead to different risk functions. But for the purposes of this post, I prefer to keep things simple. See [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) of my Econ 722 slides for more detail.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref6)
7. Remember that there are two equivalent definitions of MSE: bias squared plus variance on the one hand and expected squared distance from the truth on the other hand.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref7) | |||||||||
| Readable Markdown | If you study enough econometrics or statistics, you’ll eventually hear someone mention “Stein’s Paradox” or the [“James-Stein Estimator”](https://en.wikipedia.org/wiki/James%E2%80%93Stein_estimator). You’ve probably learned in your introductory econometrics course that ordinary least squares (OLS) is the [best linear unbiased estimator](https://en.wikipedia.org/wiki/Gauss%E2%80%93Markov_theorem) (BLUE) in a linear regression model under the Gauss-Markov assumptions. The stipulations “linear” and “unbiased” are crucial here. If we remove them, it’s possible to do better–maybe even *much better*–than OLS.[1](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn1) Stein’s paradox is a famous example of this phenomenon, one that created much consternation among statisticians and fellow-travelers when it was first pointed out by [Charles Stein](https://en.wikipedia.org/wiki/Charles_M._Stein) in the mid-1950s. The example is interesting in its own right, but also has deep connections to ideas in Bayesian inference and machine learning making it much more than a mere curiosity.
The supposed [paradox](https://youtu.be/XXhJKzI1u48?si=cS--uLd09_JnAXdr) is most simply stated by considering a special case of linear regression–that of estimating multiple unknown means. [Efron & Morris (1977)](https://www.jstor.org/stable/24954030) introduce the basic idea as follows:
> A baseball player who gets seven hits in 20 official times at bat is said to have a batting average of .350. In computing this statistic we are forming an estimate of the player’s true batting ability in terms of his observed average rate of success. Asked how well the player will do in his next 100 times at bat, we would probably predict 35 more hits. In traditional statistical theory it can be proved that no other estimation rule is uniformly better than the observed average. The paradoxical element in Stein’s result is that it sometimes contradicts this elementary law of statistical theory. If we have three or more baseball players, and if we are interested in predicting future batting averages for each of them, then there is a procedure that is better than simply extrapolating from the three separate averages. Here “better” has a strong meaning. The statistician who employs Stein’s method can expect to predict the future averages more accurately no matter what the true batting abilities of the players may be.
I first encountered Stein’s Paradox in an offhand remark by my PhD supervisor. I dutifully looked it up in an attempt to better understand the point he had been making, but lacked sufficient understanding of decision theory at the time to see what the fuss was all about. The second time I encountered it, after I knew a bit more, it seemed astounding: almost like magic. I decided to include the topic in my [Econ 722](https://ditraglia.com/econ722) course at Penn, but struggled to make it accessible to my students. A big problem, in my view, is that the proof–see [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) or [section 7.3](https://ditraglia.com/econ722/main.pdf)–is ultimately a bit of a let-down: algebra, followed by repeated integration by parts, and then a fact about the existence of moments for an [inverse-chi-squared random variable](https://en.wikipedia.org/wiki/Inverse-chi-squared_distribution). It seems like a sterile technical exercise when in fact that result itself is deep, surprising, and important. As if a benign deity were keen on making my point for me, the wikipedia article on the [James-Stein Estimator](https://en.wikipedia.org/wiki/James%E2%80%93Stein_estimator) is flagged as “may be too technical for readers to understand” at the time of this writing\!
After six months of pondering, this post is my attempt to explain the James-Stein Estimator in a way that is accessible to a broad audience. The assumed background is minimal: just an introductory course in probability and statistics. I’ll show how we can arrive at something that is *very nearly* the James-Stein estimator by following some very simple and natural intuition. After you understand my “not quite James-Stein” estimator, it’s a short step to the real thing. So the “let-down” proof I mentioned before becomes merely a technical justification for a slight modification of a formula that is already intuitively compelling. As far as possible, I’ve tried to keep this post self-contained by introducing, or at least reviewing, key background material as we go along. The cost of this approach, unfortunately, is that the post is pretty long! I hope you’ll soldier on to the end and that you’ll find the payoff worth your time and effort.
As far as I know, the precise way that I motivate the James-Stein estimator in this post is new, but there are many other papers that aim to make sense of the supposed paradox in an intuitive way. In keeping with my injunction that you should always consider [reading something else instead](https://www.econometrics.blog/post/how-to-read-an-econometrics-paper/), here are a few references that you may find helpful. [Efron & Morris (1977)](https://www.jstor.org/stable/24954030) is a classic article aimed at the general reader without a background in statistics. [Stigler (1988)](https://projecteuclid.org/journals/statistical-science/volume-5/issue-1/The-1988-Neyman-Memorial-Lecture--A-Galtonian-Perspective-on/10.1214/ss/1177012274.full) is a more technical but still accessible discussion of the topic while [Casella (1985)](https://www.jstor.org/stable/2682801) is a very readable paper that discusses the James-Stein estimator in the context of empirical Bayes. A less well-known paper that I found helpful is [Ijiri & Leitch (1980)](https://www.jstor.org/stable/2490394), who consider the James-Stein estimator in a real-world setting, namely “Audit Sampling” in accounting. They discuss several interesting practical and philosophical issues including the distinction between “composite” and “individual” risk that I’ll pick up on below.
## Warm-up Exercise
This section provides some important background that we’ll need to understand Stein’s Paradox later in the post reviewing the ideas of **bias**, **variance** and **mean-squared error** along with introducing a very simple **shrinkage estimator**. To make these ideas as transparent as possible we’ll start with a ridiculously simple problem. Suppose that you observe X ∼ Normal ( μ , 1 ), a single draw from a normal distribution with variance one and unknown mean μ. Your task is to estimate μ. This may strike you as a very silly problem: it only involves a single datapoint and we assume the variance of X is one! But in fact there’s nothing special about n \= 1 and a variance of one: these merely make the notation simpler. If you prefer, you can think of X as the sample mean of n iid draws from a population with unknown mean μ where we’ve *rescaled* everything to have variance one. So how should we estimate μ? A natural and reasonable idea is to use the sample mean, in this case X itself. This is in fact the [maximum likelihood estimator](https://en.wikipedia.org/wiki/Maximum_likelihood_estimation) for μ, so I’ll define μ ^ ML \= X. But is this estimator any good? And can we find something better?
### Review of Bias, Variance and MSE
The concepts of *bias* and *variance* are key ideas that we typically reach for when considering the quality of an estimator. To refresh your memory, *bias* is the difference between an estimators expected value and the true value of the parameter being estimated while *variance* is the expected squared difference between an estimator and its expected value. So if θ ^ is an estimator of some unknown parameter θ, then Bias ( θ ^ ) \= E \[ θ ^ \] − θ while Var ( θ ^ ) \= E \[ ( θ ^ − E \[ θ ^ \] ) 2 \]. A bias of zero means that an estimator is *correctly centered*: its expectation equals the truth. We say that such an estimator is *unbiased*.[2](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn2) A small variance means that an estimator is *precise*: it doesn’t “jump around” too much. Ideally we’d like an estimator that is correctly centered and precise. But it turns out that there is generally a *trade-off* between bias and variance: if you want to reduce one of them, you have to accept an increase in the other.
A common way of trading off bias and variance relies on a concept called *mean-squared error* (MSE) defined as the *sum* of the squared bias and the variance.[3](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn3) In particular: MSE ( θ ^ ) \= Var ( θ ^ ) \+ Bias ( θ ^ ) 2. Equivalently, we can write MSE ( θ ^ ) \= E \[ ( θ ^ − θ ) 2 \].[4](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn4) To borrow some terminology from introductory microeconomics, you can think of MSE as the *negative* of a utility function over bias and variance. Both bias and variance are “bads” in that we’d rather have less rather than more of each. This formula expresses our *preferences* in terms of how much of one we’d be willing to accept in exchange for less of the other. Slightly foreshadowing something that will come later in this post, we can think of MSE as the square of the average distance that an archer’s arrows land from the bulls-eye. Smaller values of MSE are better: variance measures how closely the arrows cluster together while bias measures how far the center of the cluster is from the bulls-eye, as in the following diagram:

### A Shrinkage Estimator
Returning to our maximum likelihood estimator: it’s unbiased, Bias ( μ ^ ML ) \= 0, so MSE ( μ ^ ML ) \= Var ( μ ^ ML ) \= 1. Suppose that low MSE is what we’re after. Is there any way to improve on the ML estimator? In other words, can we achieve an MSE that’s lower than one? The answer turns out to be *yes*. Here’s the idea. Suppose we had some reason to believe that the true mean μ isn’t very large. Then perhaps we could try to adjust our maximum likelihood estimate by *shrinking* slightly towards zero. One way to do this would be by taking a weighted average of the ML estimator and zero: μ ^ ( λ ) \= ( 1 − λ ) × μ ^ ML \+ λ × 0 \= ( 1 − λ ) X for 0 ≤ λ ≤ 1. The constant ( 1 − λ ) is called the “shrinkage factor” and controls how the ML estimator gets pulled towards zero.[5](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn5) We get a different estimator for every value of λ. If λ \= 0 then we get the ML estimator back. If λ \= 1 then we get a very silly estimator that ignores the data and simply reports zero no matter what! So let’s see how the MSE depends on our choice of λ. Substituting the definition of μ ^ ( λ ) into the formulas for bias and variance gives: Bias \[ μ ^ ( λ ) \] \= E \[ ( 1 − λ ) μ ^ ML \] − μ \= ( 1 − λ ) E \[ μ ^ ML \] − μ \= ( 1 − λ ) μ − μ \= − λ μ Var \[ μ ^ ( λ ) \] \= Var \[ ( 1 − λ ) μ ^ ML \] \= ( 1 − λ ) 2 Var \[ μ ^ ML \] \= ( 1 − λ ) 2 MSE \[ μ ^ ( λ ) \] \= Var \[ μ ^ ( λ ) \] \+ Bias \[ μ ^ ( λ ) \] 2 \= ( 1 − λ ) 2 \+ λ 2 μ 2 Unless λ \= 0, the shrinkage estimator is *biased*. And while the MSE of the ML estimator is always one, regardless of the true value of μ, the MSE of the shrinkage estimator *depends on the unknown parameter* μ.
So why should we use a biased estimator? The answer is that by tolerating a small amount of bias we may be able to achieve a *larger* reduction in variance, resulting in a lower MSE compared to the higher variance but unbiased ML estimator. A quick plot shows us that the shrinkage estimator *can indeed* have a lower MSE than the ML estimator depending on the value of λ and the true value of μ:
```
# Range of values for the unknown parameter mu
mu <- seq(-4, 4, length = 100)
# Try three different values of lambda
lambda1 <- 0.1
lambda2 <- 0.2
lambda3 <- 0.3
# Plot the MSE of the shrinkage estimator as a function of mu for all
# three values of lambda at once
matplot(mu, cbind((1 - lambda1)^2 + lambda1^2 * mu^2,
(1 - lambda2)^2 + lambda2^2 * mu^2,
(1 - lambda3)^2 + lambda3^2 * mu^2),
type = 'l', lty = 1, lwd = 2,
col = c('red', 'blue', 'green'),
xlab = expression(mu), ylab = 'MSE',
main = 'MSE of Shrinkage Estimator')
# Add legend
legend('topright', legend = c(expression(lambda == 0.1),
expression(lambda == 0.2),
expression(lambda == 0.3)),
col = c('red', 'blue', 'green'), lty = 1, lwd = 2)
# Add dashed line for MSE of ML estimator
abline(h = 1, lty = 2, lwd = 2)
```

### Some Algebra
It’s time for some algebra. If you’re tempted to skip this *please don’t*: this section is a warm-up for our main event. If you thoroughly understand the mechanics of shrinkage in this simple example, everything that follows below will seem much more natural.
As seen from the plot above, the MSE of our shrinkage estimator (the solid lines) is lower than that of the ML estimator (the dashed line) provided that our chosen value of λ isn’t too large relative to the true value of μ. With a bit of algebra, we can work out *precisely* how large λ can be to make shrinkage worthwhile. Since MSE \[ μ ^ ML \] \= 1, by expanding and simplifying the expression for MSE \[ μ ^ ( λ ) \] we see that MSE \[ μ ^ ( λ ) \] \< MSE \[ μ ^ ML \] if and only if ( 1 − λ ) 2 \+ λ 2 μ 2 \< 1 1 − 2 λ \+ λ 2 \+ λ 2 μ 2 \< 1 λ 2 ( 1 \+ μ 2 ) − 2 λ \< 0 λ \[ λ ( 1 \+ μ 2 ) − 2 \] \< 0\. Since λ ≥ 0, the final inequality can only hold if the factor inside the square brackets is negative, i.e. λ ( 1 \+ μ 2 ) − 2 \< 0 λ \< 2 1 \+ μ 2 . This shows that any choice of λ between 0 and 2 / ( 1 \+ μ 2 ) will give us a shrinkage estimator with an MSE less than one. To check our algebra, we can change the inequality to an equality and solve for μ to obtain the boundary of the region where shrinkage is better than ML: λ ( 1 \+ μ 2 ) − 2 \= 0 1 \+ μ 2 \= 2 / λ μ \= ± 2 / λ − 1 . Adding these boundaries to a simplified version of our previous plot with only λ \= 0\.3 we see that everything works out correctly: the dashed red lines intersect the blue curve at the points where the MSE of the shrinkage estimator equals that of the ML estimator.
```
# Plot the MSE of the shrinkage estimator as a function of mu for lambda = 0.3
lambda <- 0.3
plot(mu, (1 - lambda)^2 + lambda^2 * mu^2, type = 'l', lty = 1, lwd = 2,
col = 'blue', xlab = expression(mu), ylab = 'MSE',
main = 'Boundary of Region Where Shrinkage is Better than ML')
# Add dashed line for MSE of ML estimator
abline(h = 1, lty = 2, lwd = 2)
# Add boundaries of region where shrinkage is better than ML estimator
abline(v = c(sqrt(2/lambda - 1), -sqrt(2/lambda - 1)), lty = 3, lwd = 2,
col = 'red')
```

But there’s still more to learn! Suppose we wanted to take things *one step further* and find the *optimal* value of λ for any given value of μ. In other words, suppose we wanted the value of λ that *minimizes* the MSE of our shrinkage estimator given a particular assumed value for μ. Since MSE \[ μ ^ ( λ ) \] is a quadratic function of λ, as shown above, this turns out to be a fairly straightforward calculation. Differentiating, d d λ MSE \[ μ ^ ( λ ) \] \= d d λ \[ ( 1 − λ ) 2 \+ λ 2 μ 2 \] \= − 2 ( 1 − λ ) \+ 2 λ μ 2 \= 2 \[ λ ( 1 \+ μ 2 ) − 1 \] d 2 d λ 2 MSE \[ μ ^ ( λ ) \] \= 2 ( 1 \+ μ 2 ) \> 0 so there is a unique global minimum at λ ∗ ≡ 1 / ( 1 \+ μ 2 ). This gives the *optimal* shrinkage factor in the sense that it minimizes the MSE of the shrinkage estimator. Substituting λ ∗ into the expression for MSE \[ μ ^ ( λ ) \] gives: MSE \[ μ ^ ( λ ∗ ) \] \= ( 1 − 1 1 \+ μ 2 ) 2 \+ ( 1 1 \+ μ 2 ) 2 μ 2 \= ( μ 2 1 \+ μ 2 ) 2 \+ ( 1 1 \+ μ 2 ) 2 μ 2 \= ( 1 1 \+ μ 2 ) 2 ( μ 4 \+ μ 2 ) \= ( 1 1 \+ μ 2 ) 2 μ 2 ( 1 \+ μ 2 ) \= μ 2 1 \+ μ 2 \< 1\.
## Stein’s Paradox
### Recap
We’re moments away from having all the ingredients we need to introduce Stein’s Paradox! But first let’s review what we’ve uncovered thus far. We’ve seen that the shrinkage estimator can improve on the ML estimator in terms of MSE provided that λ is chosen judiciously: it needs to be between zero and 2 / ( 1 \+ μ 2 ). The optimal choice of λ, namely λ ∗ \= 1 / ( 1 \+ μ 2 ), gives an MSE of μ 2 / ( 1 \+ μ 2 ). This is always lower than one, the MSE of the ML estimator.
There’s just one massive problem we’ve ignored this whole time: **we don’t know the value of** μ! As seen from the figure plotted above, the MSE curves for different values of λ *cross each other*: the best one to use depends on the true value of μ. This doesn’t mean that all is lost. Perhaps in practice we have some outside information about the likely value of μ that could help guide our choice of λ. What it does mean is that there’s no “one-size-fits-all” value.
### Admissibility
It’s time to introduce a bit of technical vocabulary. We say that an estimator θ ~ **dominates** another estimator θ ^ if MSE \[ θ ~ \] ≤ MSE \[ θ ^ \] for *all* possible values of the parameter θ being estimated and MSE \[ θ ~ \] \< MSE \[ θ ^ \] for at least *one* possible value of θ.[6](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn6) In words, this means that it never makes sense to use θ ^ in preference to θ ~. No matter what the true parameter value is, you can’t do worse with θ ~ and you might do better. An estimator that is *not dominated* by any other estimator is called **admissible**; an estimator that *is dominated* by some other estimator is called **inadmissible**. The concept of *admissibility* in decision theory is a bit like the concept of [Pareto efficiency](https://en.wikipedia.org/wiki/Pareto_efficiency) in microeconomics. An admissible estimator is only “good” in the sense that it doesn’t leave any money on the table: there’s no way to do better for one parameter value without doing worse for another. In a similar way, a Pareto efficient allocation in economics is one in which no individual can be made better off without making another person worse off.
It’s quite challenging to prove, but in fact the ML estimator θ ^ M L \= X turns out to be admissible in our little example. So while we could potentially do better by using shrinkage, it’s not a slam-dunk case. If we really have no idea of how large μ is likely to be, the ML estimator is a reasonable choice. Because it’s admissible, at the very least we know that there’s no free lunch\!
### A More General Example
Now let’s make things a bit more interesting. For the rest of this post, suppose that we observe not a single draw X from a Normal ( μ , 1 ) distribution but a *collection* of p independent draws from p *different* normal distributions: X 1 , X 2 , . . . , X p ∼ independent Normal ( μ j , 1 ) , j \= 1 , . . . , p . You can think of this as p copies of our original problem: we observe X j ∼ Normal ( μ j , 1 ) and our task is to estimate μ j. The observations are all independent, and each comes from a distribution with a potentially **different mean**. At first glance it seems like these p separate problems should have *absolutely nothing to do with each other*. And indeed the maximum likelihood estimator for the collection of p means is simply μ ^ ML ( j ) \= X j. As above in our example with p \= 1, the question is: how good is the ML estimator, and can we do any better?
### Composite MSE
But first things first: how can we evaluate the quality of p estimators for p different parameters *at the same time*? A common approach, and the one we will follow here, is to take the *sum* of the individual MSEs of each estimator, yielding a quantity called **composite MSE**. If μ ^ 1 , μ ^ 2 , … , μ ^ p is a collection of estimators for each of the individual unknown means, then the composite MSE is defined as Composite MSE ≡ ∑ j \= 1 p MSE ( μ ^ j ) \= ∑ j \= 1 p \[ Bias ( μ ^ j ) 2 \+ Var ( μ ^ j ) \] \= ∑ j \= 1 p E \[ ( μ ^ j − μ j ) 2 \] . Adopting composite MSE as our measure of *good* performance means that we view each of the p estimation problems as in some way “interchangeable”–we’re happy to accept a trade in which we do a slightly worse job estimating μ j in exchange for doing a much better job estimating μ k. At the end of the post I’ll say a few more words about this idea and when it may or may not be reasonable. But for the rest of the post, we will assume that our goal is to **minimize the composite MSE**. The concept of composite MSE will be crucial in understanding why the James-Stein estimator works the way it does.
### Stein’s Paradox
Putting our new idea into practice, we see that the composite MSE of the ML estimator is p regardless of the true values of the individual means μ 1 , … , μ p since ∑ j \= 1 p MSE \[ μ ^ ML ( j ) \] \= ∑ j \= 1 p MSE ( X j ) \= ∑ j \= 1 p Var ( X j ) \= p . If the ML estimator is admissible, then there should be no other estimator that always has an MSE less than or equal to p and sometimes has an MSE strictly less than p. I’ve already told you that this is true when p \= 1. When p \= 2 it’s still true: the ML estimator remains admissible. But when p ≥ 3 something very unexpected happens: it becomes possible to construct an estimator that **dominates** the ML estimator by using information from *all* of the ( X 1 , . . . , X p ) observations to estimate μ j. This is spite of the fact that there is *no obvious connection* between the observations. Again: they are all independent and come from distributions with different means\!
The estimator that does the trick is the so-called “James-Stein Estimator” (JS), defined according to μ ^ JS ( j ) \= ( 1 − p − 2 ∑ k \= 1 p X k 2 ) X j . This estimator dominates the ML estimator when p ≥ 3 in that
∑ j \= 1 p MSE \[ μ ^ JS ( j ) \] ≤ ∑ j \= 1 p MSE \[ μ ^ ML ( j ) \] \= p for *all* possible values of the p unknown means μ j with strict inequality for at least *some* values. Taking a closer look at the formula, we see that the James-Stein estimator is just a *shrinkage* estimator applied to each of the p means, namely μ ^ JS ( j ) \= ( 1 − λ ^ JS ) X j , λ ^ JS ≡ p − 2 ∑ k \= 1 p X k 2 . The shrinkage factor in the James-Stein estimator depends on the number of means we’re estimating, p, along with the *overall* sum of the squared observations. All else equal, the more parameters we need to estimate, the more we shrink each of them towards zero. And the farther the observations are from zero *overall*, the less we shrink *each of them* towards zero.
Just like our simple shrinkage estimator from above, the James-Stein estimator achieves a lower MSE by tolerating a small bias in exchange for a larger reduction in variance, compared to the higher-variance but unbiased ML estimator. Unlike our simple shrinkage estimator, the James-Stein estimator uses the *data* to determine the shrinkage factor. And as long as p ≥ 3 it is always *at least as good* as the ML estimator and sometimes *much better*. The **paradox** is that this seems impossible: how can information from *all* of the observations be useful when they come from *different* distributions with no obvious connection?
The rest of this post will *not* prove that the James-Stein estimator dominates the ML estimator. Instead it will try to convince you that there is some *very good intuition* for why the formula for the James-Stein estimator takes the form it does. By the end, I hope you’ll feel that, far from seeming paradoxical, using *all* of the observations to determine the shrinkage factor for one particular μ j makes perfect sense.
## Where does the James-Stein Estimator Come From?
### An Infeasible Estimator When p \= 2
To start the ball rolling, let’s [assume a can-opener](https://en.wikipedia.org/wiki/Assume_a_can_opener): suppose that we don’t know any of the *individual* means μ j but for some strange reason a benevolent deity has told us the value of their sum of squares: c 2 ≡ ∑ j \= 1 p μ j 2 . It turns out that this is enough information to construct a shrinkage estimator that *always* has a lower composite MSE than the ML estimator. Let’s see why this is the case. If p \= 1, then telling you c 2 is the same as telling you μ 2. Granted, knowledge of μ 2 isn’t as informative as knowledge of μ. For example, if I told you that μ 2 \= 9 you couldn’t tell whether μ \= 3 or μ \= − 3. But, as we showed above, the optimal shrinkage estimator when p \= 1 sets λ ∗ \= 1 / ( 1 \+ μ 2 ) and yields an MSE of μ 2 / ( 1 \+ μ 2 ) \< 1. Since λ ∗ only depends on μ through μ 2, we’ve *already shown* that knowledge of c 2 allows us to construct a shrinkage estimator that dominates the ML estimator when p \= 1.
So what if p equals 2? In this case, knowledge of c 2 \= μ 1 2 \+ μ 2 2 is equivalent to knowing the *radius* of a circle centered at the origin in the ( μ 1 , μ 2 ) plane where the two unknown means must lie. For example, if I told you that c 2 \= 1 you would know that ( μ 1 , μ 2 ) lies somewhere on a circle of radius one centered at the origin. As illustrated in the following plot, the points ( x 1 , x 2 ) and ( y 1 , y 2 ) would then be potential values of ( μ 1 , μ 2 ) as would all other points on the blue circle.

So how can we construct a shrinkage estimator of ( μ 1 , μ 2 ) with lower composite MSE than the ML estimator if c 2 is known? While there are other possibilities, the simplest would be to use the *same* shrinkage factor for each of the two coordinates. In other words, our estimator would be μ ^ 1 ( λ ) \= ( 1 − λ ) X 1 , μ ^ 2 ( λ ) \= ( 1 − λ ) X 2 for some λ between zero and one. The composite MSE of this estimator is just the sum of the MSE of each *individual* component, so we can re-use our algebra from above to obtain MSE \[ μ ^ 1 ( λ ) \] \+ MSE \[ μ ^ 2 ( λ ) \] \= \[ ( 1 − λ ) 2 \+ λ 2 μ 1 2 \] \+ \[ ( 1 − λ ) 2 \+ λ 2 μ 2 2 \] \= 2 ( 1 − λ ) 2 \+ λ 2 ( μ 1 2 \+ μ 2 2 ) \= 2 ( 1 − λ ) 2 \+ λ 2 c 2 . Notice that the composite MSE only depends on ( μ 1 , μ 2 ) through their sum of squares, c 2. Differentiating with respect to λ, just as we did above in the p \= 1 case, d d λ \[ 2 ( 1 − λ ) 2 \+ λ 2 c 2 \] \= − 4 ( 1 − λ ) \+ 2 λ c 2 \= 2 \[ λ ( 2 \+ c 2 ) − 2 \] d 2 d λ 2 \[ 2 ( 1 − λ ) 2 \+ λ 2 c 2 \] \= 2 ( 2 \+ c 2 ) \> 0 so there is a unique global minimum at λ ∗ \= 2 / ( 2 \+ c 2 ). Substituting this value of λ into the expression for the composite MSE, a few lines of algebra give MSE \[ μ ^ 1 ( λ ∗ ) \] \+ MSE \[ μ ^ 2 ( λ ∗ ) \] \= 2 ( 1 − 2 2 \+ c 2 ) 2 \+ ( 2 2 \+ c 2 ) 2 c 2 \= 2 ( c 2 2 \+ c 2 ) . Since c 2 / ( 2 \+ c 2 ) \< 1 for all c 2 \> 0, the optimal shrinkage estimator *always* has a composite MSE less than 2, the composite MSE of the ML estimator. Strictly speaking this estimator is **infeasible** since we don’t know c 2. But it’s a crucial step on our journey to make the leap from applying shrinkage to an estimator for a *single* unknown mean, to using the same idea for *more than one* unknown mean.
### A Simulation Experiment for p \= 2
You may have already noticed that it’s easy to generalize this argument to p \> 2. But before we consider the general case, let’s take a moment to understand the geometry of shrinkage estimation for p \= 2 a bit more deeply. The nice thing about two-dimensional problems is that they’re easy to plot. So here’s a graphical representation of both the ML estimator and our infeasible optimum shrinkage estimator when p \= 2. I’ve set the true, unknown, values of μ 1 and μ 2 to one so the true value of c 2 is 2 and the optimal choice of λ is λ ∗ \= 2 / ( 2 \+ c 2 ) \= 2 / 4 \= 0\.5. The following R code simulates our estimators and visualizes their performance, helping us see the shrinkage effect in action.
```
set.seed(1983)
nreps <- 50
mu1 <- mu2 <- 1
x1 <- mu1 + rnorm(nreps)
x2 <- mu2 + rnorm(nreps)
csq <- mu1^2 + mu2^2
lambda <- csq / (2 + csq)
par(mfrow = c(1, 2))
# Left panel: ML Estimator
plot(x1, x2, main = 'MLE', pch = 20, col = 'black', cex = 2,
xlab = expression(mu[1]), ylab = expression(mu[2]))
abline(v = mu1, lty = 1, col = 'red', lwd = 2)
abline(h = mu2, lty = 1, col = 'red', lwd = 2)
# Add MSE to the plot
text(x = 2, y = 3, labels = paste("MSE =",
round(mean((x1 - mu1)^2 + (x2 - mu2)^2), 2)))
# Right panel: Shrinkage Estimator
plot(x1, x2, main = 'Shrinkage', xlab = expression(mu[1]),
ylab = expression(mu[2]))
points(lambda * x1, lambda * x2, pch = 20, col = 'blue', cex = 2)
segments(x0 = x1, y0 = x2, x1 = lambda * x1, y1 = lambda * x2, lty = 2)
abline(v = mu1, lty = 1, col = 'red', lwd = 2)
abline(h = mu2, lty = 1, col = 'red', lwd = 2)
abline(v = 0, lty = 1, lwd = 2)
abline(h = 0, lty = 1, lwd = 2)
# Add MSE to the plot
text(x = 2, y = 3, labels = paste("MSE =",
round(mean((lambda * x1 - mu1)^2 +
(lambda * x2 - mu2)^2), 2)))
```

My plot has two panels. The left panel shows the raw data. Each black point is a pair ( X 1 , X 2 ) of independent normal draws with means ( μ 1 \= 1 , μ 2 \= 1 ) and variances ( 1 , 1 ). As such, each point is also the *ML estimate* (MLE) of ( μ 1 , μ 2 ) based on ( X 1 , X 2 ). The red cross shows the location of the true values of ( μ 1 , μ 2 ), namely ( 1 , 1 ). There are 50 points in the plot, representing 50 replications of the simulation, each independent of the rest and with the same parameter values. This allows us to measure how close the ML estimator is to the true value of ( μ 1 , μ 2 ) in repeated sampling, approximating the composite MSE.
The right panel is more complicated. This shows *both* the ML estimates (unfilled black circles) *and* the corresponding shrinkage estimates (filled blue circles) along with dashed lines connecting them. Each shrinkage estimate is constructed by “pulling” the corresponding MLE towards the origin by a factor of λ \= 0\.5. Thus, if a given unfilled black circle is located at ( X 1 , X 2 ), the corresponding filled blue circle is located at ( 0\.5 X 1 , 0\.5 X 2 ). As in the left panel, the red cross in the right panel shows the true values of ( μ 1 , μ 2 ), namely ( 1 , 1 ). The black cross, on the other hand, shows the point towards which the shrinkage estimator pulls the ML estimator, namely ( 0 , 0 ).
We see immediately that the ML estimator is *unbiased*: the black filled dots in the left panel (along with the unfilled ones in the right) are centered at ( 1 , 1 ). But the ML estimator is also *high-variance*: the black dots are quite spread out around ( 1 , 1 ). We can approximate the composite MSE of the ML estimator by computing the average squared Euclidean distance between the black points and the red cross.[7](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fn7) And in keeping with our theoretical calculations, the simulation gives a composite MSE of almost exactly 2 for the ML estimator.
In contrast, the optimal shrinkage estimator is *biased*: the filled blue dots in the right panel centered somewhere between the red cross (the true means) and the origin. But the shrinkage estimator also has a lower variance: the filled blue dots are much closer together than the black ones. Even more importantly *they are on average closer to* ( μ 1 , μ 2 ), as indicated by the red cross and as measured by composite MSE. Our theoretical calculations showed that the composite MSE of the optimal shrinkage estimator equals 2 c 2 / ( 2 \+ c 2 ). When c 2 \= 2, as in this case, we obtain 2 × 2 / ( 2 \+ 2 ) \= 1. Again, this is almost exactly what we see in the simulation.
If we had used more than 50 simulation replications, the composite MSE values would have been even closer to our theoretical predictions, at the cost of making the plot much harder to read! But I hope the key point is still clear: shrinkage *pulls* the MLE towards the origin, and can give a *much* lower composite MSE.
### An Infeasible Estimator: The General Case
Now that we understand the case of p \= 2, the general case is a snap. Our shrinkage estimator of each μ j will take the form μ ^ j ( λ ) \= ( 1 − λ ) X j , j \= 1 , … , p for some λ between zero and one. To find the optimal choice of λ, we minimize ∑ j \= 1 p MSE \[ μ ^ j ( λ ) \] \= ∑ j \= 1 p \[ ( 1 − λ ) 2 \+ λ 2 μ j 2 \] \= p ( 1 − λ ) 2 \+ λ 2 c 2 with respect to λ. Again, the key is that the composite MSE only depends on the unknown means through c 2. Using almost exactly the same calculations as above for the case of p \= 2, we find that λ ∗ \= p p \+ c 2 , ∑ j \= 1 p MSE \[ μ ^ j ( λ ∗ ) \] \= p ( c 2 p \+ c 2 ) . since c 2 / ( p \+ c 2 ) \< 1 for all c 2 \> 0, the optimal shrinkage estimator *always* has a composite MSE less than p, the composite MSE of the ML estimator.
### Not Quite the James-Stein Estimator
The end is in sight! We’ve shown that if we knew the sum of squares of the unknown means, c 2, we could construct a shrinkage estimator that always has a lower composite MSE than the ML estimator. But we don’t know c 2. So what can we do? To start off, re-write λ ∗ as follows λ ∗ \= p p \+ c 2 \= 1 1 \+ c 2 / p . This way of writing things makes it clear that it’s not c 2 *per se* that matters but rather c 2 / p. And this quantity is simply is the *average* of the unknown squared means: c 2 p \= 1 p ∑ j \= 1 p μ j 2 . So how could we learn c 2 / p? An idea that immediately suggests itself is to estimate this quantity by replacing each unobserved μ j with the corresponding observation X j, in other words 1 p ∑ j \= 1 p X j 2 . This is a good starting point, but we can do better. Since X j ∼ Normal ( μ j , 1 ), we see that E \[ 1 p ∑ j \= 1 p X j 2 \] \= 1 p ∑ j \= 1 p E \[ X j 2 \] \= 1 p ∑ j \= 1 p \[ Var ( X j ) \+ E ( X j ) 2 \] \= 1 p ∑ j \= 1 p ( 1 \+ μ j 2 ) \= 1 \+ c 2 p . This means that ( ∑ j \= 1 p X j 2 ) / p will on average *overestimate* c 2 / p by one. But that’s a problem that’s easy to fix: simply subtract one! This is a rare situation in which there is *no bias-variance tradeoff*. Subtracting a constant, in this case one, doesn’t contribute any additional variation while completely removing the bias. Plugging into our formula for λ ∗, this suggests using the estimator λ ^ ≡ 1 1 \+ \[ ( 1 p ∑ j \= 1 p X j 2 ) − 1 \] \= 1 1 p ∑ j \= 1 p X j 2 \= p ∑ j \= 1 p X j 2 as our stand-in for the unknown λ ∗, yielding a shrinkage estimator that I’ll call “NQ” for “not quite” for reasons that will become apparent in a moment: μ ^ NQ ( j ) \= ( 1 − p ∑ k \= 1 p X k 2 ) X j . Notice what’s happening here: our optimal shrinkage estimator depends on c 2 / p, something we can’t observe. But we’ve constructed an *unbiased estimator* of this quantity by using *all of the observations* X j. This is the resolution of the paradox discussed above: all of the observations contain information about c 2 since this is simply the sum of the squared means. And because we’ve chosen to minimize composite MSE, the optimal shrinkage factor only depends on the individual μ j parameters through c 2! This is the sense in which it’s possible to learn something useful about, say, μ 1 from X 2 in spite of the fact that E \[ X 2 \] \= μ 2 may bear no relationship to μ 1.
But wait a minute! This looks *suspiciously familiar*. Recall that the James-Stein estimator is given by μ ^ JS ( j ) \= ( 1 − p − 2 ∑ k \= 1 p X k 2 ) X j . Just like the JS estimator, my NQ estimator shrinks each of the p means towards zero by a factor that depends on the number of means we’re estimating, p, and the overall sum of the squared observations. The key difference between JS and NQ is that JS uses p − 2 in the numerator instead of p. This means that NQ is a more “aggressive” shrinkage estimator than JS: it pulls the means towards zero by a larger amount than JS. This difference turns out to be crucial for proving that the JS estimator dominates the ML estimator. But when it comes to understanding why the JS estimator has the *form* that it does, I would argue that the difference is minor. If you want all the gory details of where that extra − 2 comes from, along with the closely related issue of why p ≥ 3 is crucial for JS to dominate the ML estimator, see [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) or [section 7.3](https://ditraglia.com/econ722/main.pdf) from my Econ 722 teaching materials.
## Conclusion
Before we conclude, there’s one important caveat to bear in mind. In addition to the qualifications that NQ isn’t *quite* JS, and that JS only dominates the MLE when p ≥ 3, there’s one more fundamental issue that could be easily missed. Our decision to minimize *composite* MSE is *absolutely crucial* to the reasoning given above. The magic of shrinkage depends on our willingness to accept a trade-off in which we do a worse job estimating one mean in exchange for doing a better job estimating another, as composite MSE imposes. Whether this makes sense in practice depends on the context.
If we’re searching for a lost submarine in the ocean (a 3-dimensional problem), it makes perfect sense to be willing to be farther from the submarine in one dimension in exchange for being closer in another. That’s because *Euclidean distance* is obviously what we’re after here. But if instead we’re estimating [teacher value-added](https://ideas.repec.org/p/nbr/nberwo/27094.html) and the results of our estimation exercise will be used to determine which teachers lose their jobs, it’s less clear that we should be willing to be farther from one teacher in exchange for being closer to another. Certainly that would be no consolation to someone who had been wrongly dismissed! If we were merely using this information to identify teachers who might need extra help, it’s another story. But the point I’m trying to make here is that our choice of which criterion to minimize necessarily encodes our *values* in a particular problem.
But with that said, I hope you’re satisfied that this extremely long post was worth the effort. Without using any fancy mathematics or statistical theory, we’ve managed to invent something that is *nearly identical* to the James-Stein estimator and thus to resolve Stein’s paradox. We started by pretending what we knew c 2 and showed that this would allow us to derive a shrinkage estimator with a lower composite MSE than the ML estimator. Then we simply plugged in an unbiased estimator of the key unknown quantity: c 2 / p. Because all the observations contain information about c 2, it makes sense that we should decide how much to shrink one component X j by using all of the others. At this point, I hope that the James-Stein estimator seems not only plausible but practically *obvious*, excepting of course that pesky − 2 in the numerator.
## Footnotes
1. If I ruled the universe, the Gauss-Markov Theorem would be demoted to much less exalted status in econometrics teaching\
2. Don’t let words do your thinking for you: “bias” sounds like a very bad thing, like kicking puppies. But that’s because the word “bias” has a negative connotation in English. In statistics, it’s just a technical term for “not centered”. An estimator can be biased and still be very good. Indeed the punchline of this post is that the James-Stein estimator is biased but can be much better than the obvious alternative\
3. Why squared bias and not simply bias itself? The answer is units: bias is measured in the same units as the parameter being estimated while the variance is in squared units. It doesn’t make sense to add things with different units, so we either have to square the bias or take the square root of the variance, i.e. replace it with the standard deviation. But bias can be negative, and we wouldn’t want a large negative bias to cancel out a large standard deviation so MSE squares the bias instead.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref3)
4. See if you can prove this as a homework exercise\
5. In Bayesian terms, we could view this “shrinkage” idea as calculating the posterior mean of μ conditional on our data X under a normal prior. In this case λ would equal τ / ( 1 \+ τ ) where τ is the *prior precision*, i.e. the reciprocal of the prior variance. But for this post we’ll mainly stick to the Frequentist perspective.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref5)
6. Strictly speaking all of this pre-supposes that we’re working with squared-error loss so that MSE is the right thing to minimize. There are other loss functions we could have used instead and these would lead to different risk functions. But for the purposes of this post, I prefer to keep things simple. See [lecture 1](https://ditraglia.com/econ722/slides/econ722slides.pdf) of my Econ 722 slides for more detail.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref6)
7. Remember that there are two equivalent definitions of MSE: bias squared plus variance on the one hand and expected squared distance from the truth on the other hand.[↩︎](https://www.econometrics.blog/post/not-quite-the-james-stein-estimator/#fnref7) | |||||||||
| ML Classification | ||||||||||
| ML Categories |
Raw JSON{
"/Science": 863,
"/Science/Mathematics": 842,
"/Science/Mathematics/Statistics": 826
} | |||||||||
| ML Page Types |
Raw JSON{
"/Article": 999,
"/Article/Tutorial_or_Guide": 789
} | |||||||||
| ML Intent Types |
Raw JSON{
"Informational": 999
} | |||||||||
| Content Metadata | ||||||||||
| Language | en | |||||||||
| Author | Francis J. DiTraglia | |||||||||
| Publish Time | not set | |||||||||
| Original Publish Time | 2024-08-13 01:53:35 (1 year ago) | |||||||||
| Republished | No | |||||||||
| Word Count (Total) | 8,363 | |||||||||
| Word Count (Content) | 8,280 | |||||||||
| Links | ||||||||||
| External Links | 19 | |||||||||
| Internal Links | 7 | |||||||||
| Technical SEO | ||||||||||
| Meta Nofollow | No | |||||||||
| Meta Noarchive | No | |||||||||
| JS Rendered | Yes | |||||||||
| Redirect Target | null | |||||||||
| Performance | ||||||||||
| Download Time (ms) | 49 | |||||||||
| TTFB (ms) | 48 | |||||||||
| Download Size (bytes) | 24,964 | |||||||||
| Shard | 7 (laksa) | |||||||||
| Root Hash | 17011614825276657407 | |||||||||
| Unparsed URL | blog,econometrics!www,/post/not-quite-the-james-stein-estimator/ s443 | |||||||||