ℹ️ Skipped - page is already crawled
| Filter | Status | Condition | Details |
|---|---|---|---|
| HTTP status | PASS | download_http_code = 200 | HTTP 200 |
| Age cutoff | PASS | download_stamp > now() - 6 MONTH | 0.9 months ago |
| History drop | PASS | isNull(history_drop_reason) | No drop reason |
| Spam/ban | PASS | fh_dont_index != 1 AND ml_spam_score = 0 | ml_spam_score=0 |
| Canonical | PASS | meta_canonical IS NULL OR = '' OR = src_unparsed | Not set |
| Property | Value | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| URL | https://www.cs.auckland.ac.nz/software/AlgAnim/hash_func.html | ||||||||||||||||||||||||
| Last Crawled | 2026-03-25 06:48:29 (28 days ago) | ||||||||||||||||||||||||
| First Indexed | 2014-01-08 01:51:25 (12 years ago) | ||||||||||||||||||||||||
| HTTP Status Code | 200 | ||||||||||||||||||||||||
| Content | |||||||||||||||||||||||||
| Meta Title | Data Structures and Algorithms: Hash Functions | ||||||||||||||||||||||||
| Meta Description | Data Structures and Algorithms Course Notes, PLDS210 University of Western Australia | ||||||||||||||||||||||||
| Meta Canonical | null | ||||||||||||||||||||||||
| Boilerpipe Text | Data Structures and Algorithms
8.3.3 Hashing Functions
Choosing a good hashing function,
h(k)
,
is essential for hash-table based searching.
h
should distribute the elements of our collection as
uniformly as possible to the "slots" of the hash table.
The key criterion is that there should be a minimum number of collisions.
If the probability that a key,
k
, occurs in our
collection is
P(k)
, then if there are
m
slots in our hash table,
a
uniform hashing function
,
h(k)
, would
ensure:
Sometimes, this is easy to ensure.
For example, if the keys are randomly distributed in
(0,
r
],
then,
h(k) = floor((mk)/r)
will provide uniform hashing.
Mapping keys to natural numbers
Most hashing functions will first map the keys
to some set of natural numbers, say (0,r].
There are many ways to do this,
for example if the key is a string of ASCII characters,
we can simply add the ASCII representations of the
characters mod 255 to produce a number in (0,255) -
or we could
xor
them,
or we could add them in pairs mod 2
16
-1,
or ...
Having mapped the keys to a set of natural numbers,
we then have a number of possibilities.
Use a
mod
function:
h(k) = k mod m
.
When using this method, we
usually avoid certain values of
m
.
Powers of 2 are usually avoided,
for
k mod 2
b
simply selects the
b
low order bits of
k
.
Unless we know that all the 2
b
possible
values of the lower order bits are equally likely,
this will not be a good choice,
because some bits of the key are not used in the hash function.
Prime numbers which are close to powers of 2
seem to be generally good choices for
m
.
For example, if we have 4000 elements, and we have
chosen an overflow table organization, but wish to
have the probability of collisions quite low,
then we might choose
m
= 4093.
(4093 is the largest prime less than 4096 = 2
12
.)
Use the multiplication method:
Multiply the key by a constant
A
,
0 <
A
< 1,
Extract the fractional part of the product,
Multiply this value by
m
.
Thus the hash function is:
h(k) = floor(m * (kA - floor(kA)))
In this case, the value of
m
is not critical and
we typically choose a power of 2 so that we can get the
following efficient procedure on most digital computers:
Choose
m
= 2
p
.
Multiply the
w
bits of
k
by
floor(A * 2
w
)
to
obtain a 2
w
bit product.
Extract the
p
most significant bits of the
lower half of this product.
It seems that:
A
= (sqrt(5)-1)/2 = 0.6180339887
is a good choice (
see
Knuth,
"Sorting and Searching", v. 3 of "The Art of Computer
Programming").
Use universal hashing:
A malicious adversary can always chose the keys
so that they all hash to the same slot,
leading to an average
O(n)
retrieval time.
Universal hashing seeks to avoid this by choosing the
hashing function randomly from a collection of hash
functions (
cf
Cormen
et al
, p 229- ).
This makes the probability that the hash function
will generate poor behaviour small and produces good
average performance.
Key terms
Universal hashing
A technique for choosing a hashing function randomly
so as to produce good average performance.
©
, 1998 | ||||||||||||||||||||||||
| Markdown | | |
|---|
| *Data Structures and Algorithms* |
| **8\.3.3 Hashing Functions** |
Choosing a good hashing function, **h(k)**, is essential for hash-table based searching. **h** should distribute the elements of our collection as uniformly as possible to the "slots" of the hash table. The key criterion is that there should be a minimum number of collisions.
If the probability that a key, **k**, occurs in our collection is **P(k)**, then if there are **m** slots in our hash table, a *uniform hashing function*, **h(k)**, would ensure:
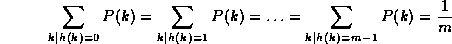
Sometimes, this is easy to ensure. For example, if the keys are randomly distributed in (0,**r**\], then,
**h(k) = floor((mk)/r)**
will provide uniform hashing.
#### Mapping keys to natural numbers
Most hashing functions will first map the keys to some set of natural numbers, say (0,r\]. There are many ways to do this, for example if the key is a string of ASCII characters, we can simply add the ASCII representations of the characters mod 255 to produce a number in (0,255) - or we could **xor** them, or we could add them in pairs mod 216\-1, or ...
Having mapped the keys to a set of natural numbers, we then have a number of possibilities.
1. Use a **mod** function:
**h(k) = k mod m**.
When using this method, we usually avoid certain values of **m**. Powers of 2 are usually avoided, for **k mod 2b** simply selects the **b** low order bits of **k**. Unless we know that all the 2**b** possible values of the lower order bits are equally likely, this will not be a good choice, because some bits of the key are not used in the hash function.
Prime numbers which are close to powers of 2 seem to be generally good choices for **m**.
For example, if we have 4000 elements, and we have chosen an overflow table organization, but wish to have the probability of collisions quite low, then we might choose **m** = 4093. (4093 is the largest prime less than 4096 = 212.)
2. Use the multiplication method:
- Multiply the key by a constant **A**, 0 \< **A** \< 1,
- Extract the fractional part of the product,
- Multiply this value by **m**.
Thus the hash function is:
**h(k) = floor(m \* (kA - floor(kA)))**
In this case, the value of **m** is not critical and we typically choose a power of 2 so that we can get the following efficient procedure on most digital computers:
- Choose **m** = 2**p**.
- Multiply the **w** bits of **k** by **floor(A \* 2w)** to obtain a 2**w** bit product.
- Extract the **p** most significant bits of the lower half of this product.
It seems that:
**A** = (sqrt(5)-1)/2 = 0.6180339887
is a good choice (*see* Knuth, "Sorting and Searching", v. 3 of "The Art of Computer Programming").
3. Use universal hashing:
A malicious adversary can always chose the keys so that they all hash to the same slot, leading to an average **O(n)** retrieval time. Universal hashing seeks to avoid this by choosing the hashing function randomly from a collection of hash functions (*cf* Cormen *et al*, p 229- ). This makes the probability that the hash function will generate poor behaviour small and produces good average performance.
| |
|---|
| Key terms |
**Universal hashing**
A technique for choosing a hashing function randomly so as to produce good average performance.
| | |
|---|---|
| Continue on to [Dynamic Algorithms](https://www.cs.auckland.ac.nz/software/AlgAnim/dynamic.html) | Back to the [Table of Contents](https://www.cs.auckland.ac.nz/software/AlgAnim/ds_ToC.html) |
© , 1998 | ||||||||||||||||||||||||
| Readable Markdown | | |
|---|
| *Data Structures and Algorithms* |
| **8\.3.3 Hashing Functions** |
Choosing a good hashing function, **h(k)**, is essential for hash-table based searching. **h** should distribute the elements of our collection as uniformly as possible to the "slots" of the hash table. The key criterion is that there should be a minimum number of collisions.
If the probability that a key, **k**, occurs in our collection is **P(k)**, then if there are **m** slots in our hash table, a *uniform hashing function*, **h(k)**, would ensure:
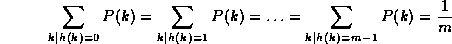
Sometimes, this is easy to ensure. For example, if the keys are randomly distributed in (0,**r**\], then,
**h(k) = floor((mk)/r)**
will provide uniform hashing.
#### Mapping keys to natural numbers
Most hashing functions will first map the keys to some set of natural numbers, say (0,r\]. There are many ways to do this, for example if the key is a string of ASCII characters, we can simply add the ASCII representations of the characters mod 255 to produce a number in (0,255) - or we could **xor** them, or we could add them in pairs mod 216\-1, or ...
Having mapped the keys to a set of natural numbers, we then have a number of possibilities.
1. Use a **mod** function:
**h(k) = k mod m**.
When using this method, we usually avoid certain values of **m**. Powers of 2 are usually avoided, for **k mod 2b** simply selects the **b** low order bits of **k**. Unless we know that all the 2**b** possible values of the lower order bits are equally likely, this will not be a good choice, because some bits of the key are not used in the hash function.
Prime numbers which are close to powers of 2 seem to be generally good choices for **m**.
For example, if we have 4000 elements, and we have chosen an overflow table organization, but wish to have the probability of collisions quite low, then we might choose **m** = 4093. (4093 is the largest prime less than 4096 = 212.)
2. Use the multiplication method:
- Multiply the key by a constant **A**, 0 \< **A** \< 1,
- Extract the fractional part of the product,
- Multiply this value by **m**.
Thus the hash function is:
**h(k) = floor(m \* (kA - floor(kA)))**
In this case, the value of **m** is not critical and we typically choose a power of 2 so that we can get the following efficient procedure on most digital computers:
- Choose **m** = 2**p**.
- Multiply the **w** bits of **k** by **floor(A \* 2w)** to obtain a 2**w** bit product.
- Extract the **p** most significant bits of the lower half of this product.
It seems that:
**A** = (sqrt(5)-1)/2 = 0.6180339887
is a good choice (*see* Knuth, "Sorting and Searching", v. 3 of "The Art of Computer Programming").
3. Use universal hashing:
A malicious adversary can always chose the keys so that they all hash to the same slot, leading to an average **O(n)** retrieval time. Universal hashing seeks to avoid this by choosing the hashing function randomly from a collection of hash functions (*cf* Cormen *et al*, p 229- ). This makes the probability that the hash function will generate poor behaviour small and produces good average performance.
### Key terms
**Universal hashing**
A technique for choosing a hashing function randomly so as to produce good average performance.
© , 1998 | ||||||||||||||||||||||||
| ML Classification | |||||||||||||||||||||||||
| ML Categories |
Raw JSON{
"/Computers_and_Electronics": 846,
"/Computers_and_Electronics/Software": 451,
"/Computers_and_Electronics/Software/Educational_Software": 321,
"/Science": 150,
"/Science/Computer_Science": 144,
"/Jobs_and_Education": 112,
"/Jobs_and_Education/Education": 112,
"/Science/Computer_Science/Machine_Learning_and_Artificial_Intelligence": 111
} | ||||||||||||||||||||||||
| ML Page Types |
Raw JSON{
"/Document": 510,
"/Document/Manual": 336
} | ||||||||||||||||||||||||
| ML Intent Types |
Raw JSON{
"Informational": 998
} | ||||||||||||||||||||||||
| Content Metadata | |||||||||||||||||||||||||
| Language | null | ||||||||||||||||||||||||
| Author | null | ||||||||||||||||||||||||
| Publish Time | not set | ||||||||||||||||||||||||
| Original Publish Time | 2014-01-08 01:51:25 (12 years ago) | ||||||||||||||||||||||||
| Republished | No | ||||||||||||||||||||||||
| Word Count (Total) | 596 | ||||||||||||||||||||||||
| Word Count (Content) | 579 | ||||||||||||||||||||||||
| Links | |||||||||||||||||||||||||
| External Links | 0 | ||||||||||||||||||||||||
| Internal Links | 2 | ||||||||||||||||||||||||
| Technical SEO | |||||||||||||||||||||||||
| Meta Nofollow | No | ||||||||||||||||||||||||
| Meta Noarchive | No | ||||||||||||||||||||||||
| JS Rendered | No | ||||||||||||||||||||||||
| Redirect Target | null | ||||||||||||||||||||||||
| Performance | |||||||||||||||||||||||||
| Download Time (ms) | 1,049 | ||||||||||||||||||||||||
| TTFB (ms) | 1,049 | ||||||||||||||||||||||||
| Download Size (bytes) | 2,150 | ||||||||||||||||||||||||
| Shard | 47 (laksa) | ||||||||||||||||||||||||
| Root Hash | 5642127877429519047 | ||||||||||||||||||||||||
| Unparsed URL | nz,ac,auckland!cs,www,/software/AlgAnim/hash_func.html s443 | ||||||||||||||||||||||||